
Buenas a todos!! Ya tenía yo ganas de poder volver y publicar la segunda parte de nuestro proyecto 🙂 Me ha gustado mucho ver que le habéis estado echando un ojo con interés a la primera parte y agradecemos infinitamente el apoyo y las peticiones de la segunda 😛
Como os decía en la primera parte, el proyecto forma parte de mi trabajo de fin de máster el año pasado junto a mi compañero Javier (perfil de github) y gracias a nuestro tutor Pablo González (@pablogonzalezpe).
Aquí os dejo dicha primera parte si aún no le habéis echado un vistazo, donde describo el proceso de obtención de las capturas de tráfico:
Dicho esto, e igual que hice (más tarde de la publicación) con la primera parte del proyecto, aquí tenéis el código liberado en GitHub 🙂 Hemos decidido utilizar una licencia GPLv3 para que podáis disfrutar libremente del código fuente para aprender, que es lo suyo.
https://github.com/hartek/AIRE-PoC
¡¡Pongámonos manos a la obra!!
Aviso
El proyecto se libera y se muestra como una prueba de concepto bajo la licencia GPL versión 3.
No debería usarse en sistemas de producción y solamente debería utilizarse para fines de aprendizaje.
Los autores no se hacen responsables, como establece la licencia, del uso que se le dé al proyecto.
Dicho esto, ¡gracias por mostrar interés en nuestro trabajo y esperemos que lo disfrutes!
Arquitectura del sistema
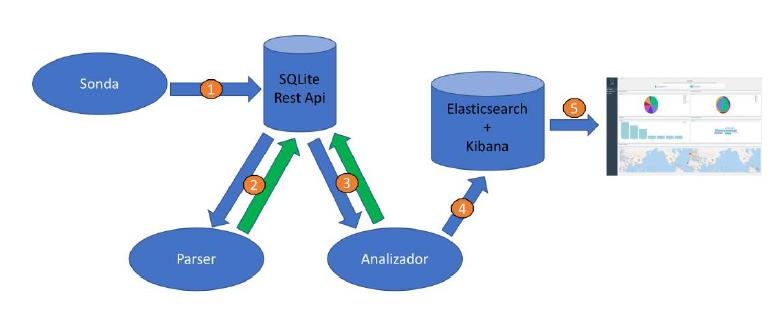
Antes de nada, conviene dar una pequeña explicación acerca de la estructura del sistema.
- Primero, la sonda se dedica a recoger paquetes de datos pcap de distintos dispositivos, y los agrupará por mac. Estos datos serán enviados vía API Rest a nuestro servidor de Django para que se guarden en una base de datos de SQLite.
- Un script se encargará de pedir los datos recientes a el servidor, mediante la API Rest, y extraerá los datos que se han considerado relevantes, guardándolos en un JSON y reenviándolo al webservice a través de la API, actualizando su estado.
- El analizador, al igual que el parseador, obtendrá de la api los datos que ya han sido parseando, y a partir del json de datos, les dará valor para luego guardarlos de nuevo en el servidor.
- A la vez que lo guarda en el servidor, realizará la indexación de los datos, guardándolos en la base de Elasticsearch a través del SDK.
- El frontal sacará los datos de la base de datos, y los mostrará para la visualización por parte del usuario.
Instalación del sistema
Puesta en marcha de Kibana y ElasticSearch
Instalación y arranque de contenedores Kibana y ElasticSearch
El proyecto se apoya en Elasticsearch para el almacenamiento y manejo de los datos ya analizados y en Kibana para su visualización.
Podemos realizar una instalación limpia de ambas utilidades siguiendo los pasos necesarios que se pueden encontrar en la documentación oficial. Sin embargo, nosotros adoptamos la solución utilizar contenedores Docker para simplificar su instalación y puesta en marcha.
En caso de preferir realizar una instalación nativa, consultar:
- https://www.elastic.co/guide/en/elasticsearch/reference/5.5/install-elasticsearch.html
- https://www.elastic.co/guide/en/kibana/5.5/install.html
Para la instalación de estos servicios utilizando Docker, necesitaremos tener instalados los paquetes tanto de Docker como de docker-compose. Para la instalación de dichos paquetes podemos consultar:
- https://docs.docker.com/install/linux/docker-ce/ubuntu
- https://docs.docker.com/compose/install/#install-compose
Una vez preparados estos requisitos, podemos ejecutar el siguiente comando desde la raíz del proyecto AIRE descargado:
sudo docker-compose up -d
El comando empezará a descargar y levantar las máquinas necesarias para Kibana y ElasticSearch de forma automática leyendo el fichero docker-compose.yml del proyecto, tras lo cual las mantendrá en segundo plano.
Configuración de Kibana
Debemos acceder ahora desde el explorador a la URL http://localhost:5601/app/kibana para realizar la configuración de Kibana.
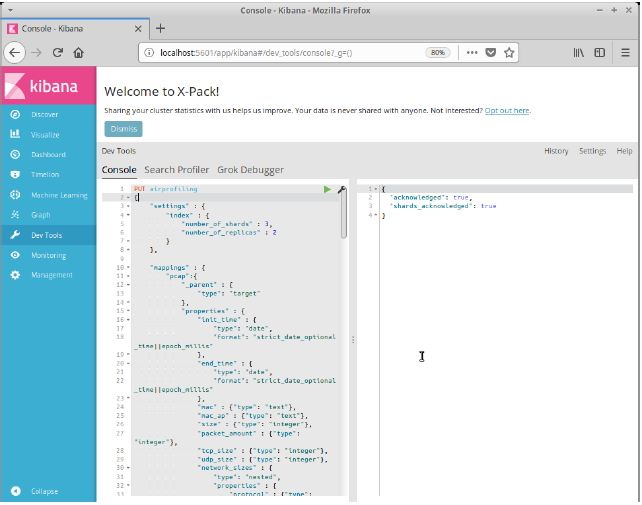
En el panel de la izquierda haremos click en Dev Tools. Se nos mostrará una consola en la que deberemos introducir el contenido del fichero airprofiling-index.json que puede encontrarse en la carpeta elasticsearch del proyecto. Haremos click en el icono de ejecutar para así crear la configuración de índices de ElasticSearch.
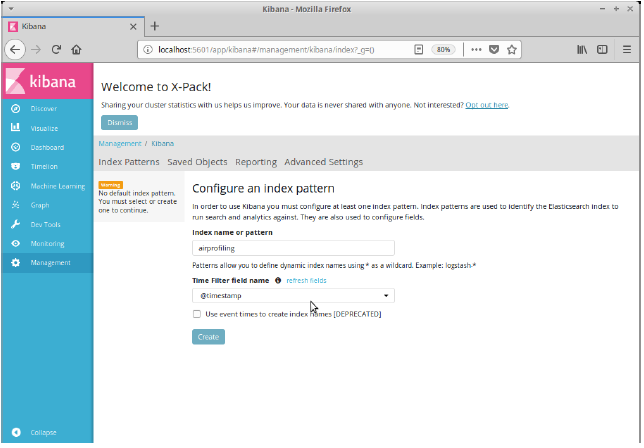
Hecho esto, haremos click en el panel izquierdo en Management. En la página que aparece, haremos click en Index Patterns dentro del apartado de Kibana. Introduciremos dentro del campo Index name or pattern el valor airprofiling, y en el campo Time Filter field name seleccionaremos @timestamp. Por último, haremos click en Create.
Vemos como ha quedado creado el índice de forma correcta. Como último paso, haremos click en Saved Objects, y en la página que se muestra haremos click en Import. Deberemos seleccionar el fichero export_kibana_objects.json que puede encontrarse en la carpeta elasticsearch del proyecto. Confirmaremos la sobreescritura en el diálogo de confirmación. De esta forma importaremos la configuración para la generación de vistas y gráficas para la página del proyecto.
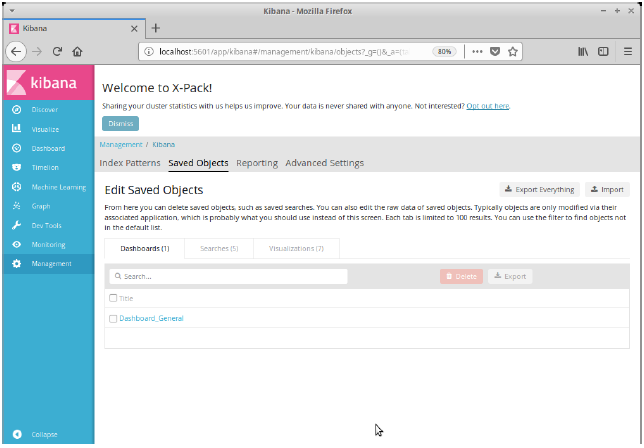
En este punto tendremos Kibana y ElasticSearch correctamente configurados para su utilización por AIRE.
Puesta en marcha del proyecto
Inicialización de la BD y creación de un usuario
El primer paso será crear un usuario que será el que acceda al panel de la aplicación. Lo primero será ejecutar los comandos necesarios para crear la base de datos y su estructura. Ejecutaremos los siguientes comandos desde la raíz del proyecto:
python3 airprofiling/manage.py makemigrations python3 airprofiling/manage.py migrate
Abriremos ahora una consola de Django ejecutando el siguiente comando desde la raíz del proyecto:
python3 airprofiling/manage.py shell
Nos aparecerá una consola de comandos para la administración del servidor. Debemos introducir los siguientes comandos, donde <usuario> y <contraseña> serán las credenciales que elijamos:
from django.contrib.auth.models import User
user=User.objects.create_user("<usuario>",password="<contraseña>")
user.is_superuser=True
user.is_staff=True
user.save()
exit()
Introducción de claves de API y tokens
Primero debemos ejecutar el siguiente comando para obtener el token de acceso del usuario que hemos creado anteriormente, utilizando sus credenciales de acceso:
http 127.0.0.1:8000/api-token-auth username=”<usuario>” password=”<contraseña>”
Nos devolverá una respuesta de esta forma:
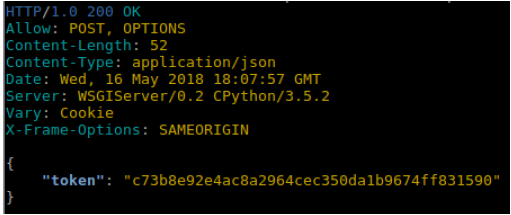
Debemos copiar el token y pegarlo en el fichero localizado en la dirección parsing/conf/ApiRestConfiguration.py desde la raíz del proyecto, como valor en la línea AUTHTOKEN. Esto nos permitirá que los scripts de extracción y análisis puedan actuar contra nuestro servidor.
Seguidamente, debemos introducir un token de la API de Fono en el fichero de configuración localizado en parsing/conf/tokens.py como valor de la línea FONO_API_TOKEN. El proyecto utiliza esta API para obtener características de modelos de terminales móviles. Podemos obtener el token en la siguiente dirección:
En ese mismo fichero debemos introducir una Access Key ID y una Secret Key válidas de acceso de para las API de Amazon. En caso del proyecto, se hace uso de la API de AWIS (Amazon Web Information Service) para la categorización de páginas web. En la siguiente página puede consultarse cómo obtenerlas:
Arranque del servidor
Por último, podremos por fin levantar el servidor de aplicación y dejarlo ejecutándose en una terminal.
python3 airprofiling/manage.py runserver
Podemos opcionalmente dejarlo ejecutándose en segundo plano:
python3 airprofiling/manage.py runserver &
En la URL http://localhost:8000/airprofiling podremos acceder a la aplicación web. Nos reenviará al principio a la pantalla de inicio de sesión, donde podremos introducir las credenciales anteriormente creados para acceder a la aplicación.
Utilización del sistema
Subida de capturas
La subida de las capturas al sistema puede hacerse mediante una llamada a su API. Podemos hacerlo desde diferentes alternativas, por ejemplo, desde curl o httpie.
Necesitaremos o bien el usuario y contraseña anteriormente creados o bien el token de acceso que obtuvimos para poder interactuar con la API y realizar la subida. Debemos además conocer tanto la dirección IP (local o remota) donde está localizado el servidor y el puerto del servicio, y la dirección local de la captura en nuestro sistema de ficheros.
El comando que ejecutar con curl es el siguiente:
curl -X POST -S -F "file=@<direccion_completa_captura>;type=application/cap" -F "description=pcap file" http://<direccion_ip>:<puerto>/pcapfiles/pcap-api/ -H -u "<usuario>:<contraseña>"
O bien:
curl -X POST -S -F "file=@<direccion_completa_captura>;type=application/cap" -F "description=pcap file" http://<direccion_ip>:<puerto>/pcapfiles/pcap-api/ -H "Authorization: Token <token>"
Se nos devolverá una respuesta de esta forma, a modo de ejemplo una vez formateado el json:
{
"id":2,
"file":"http://<direccion_ip>:<puerto>/pcapfiles/pcap-api/uploads/<captura>.pcap",
"name":"<captura>",
"description":"pcap file",
"created":"2018-05-18T18:05:18.061937Z",
"updated":"2018-05-18T18:05:18.061972Z",
"size":67250409,
"owner":1,
"status":0,
"parsed_json":"",
"analyzed_date":null,
"analyzed_json":""
}

Ejecución de la extracción y el análisis
Tanto la extracción como el análisis se realizan invocando un script del proyecto desde la máquina servidor en la que esté corriendo el servicio. Estos scripts están localizados en parsing/bin/parsePcapService.py (extracción) y en parsing/bin/analyzeAndIndexData.py (análisis).
Pueden invocarse puntualmente de forma manual para realizar la extracción y posteriormente el análisis de las nuevas capturas subidas, o bien de forma automatizada mediante invocación desde otros scripts o desde cron.
De cualquier manera, pueden invocarse desde la misma raíz del proyecto con los siguientes comandos:
python3 parsing/bin/parsePcapService.py python3 parsing/bin/analyzeAndIndexData.py
Los scripts además reintentarán el proceso sobre capturas que anteriormente hayan fallado por errores de conexión o cualquier otra causa.
Visualización y exploración de los datos
Una vez extraídos y analizados los datos, podremos ir a nuestra aplicación web alojada en el servidor, en la dirección http://localhost:8000/airprofiling si accedemos desde el mismo. Podemos navegar desde el menú lateral por las diferentes secciones de la aplicación.
Dashboard.

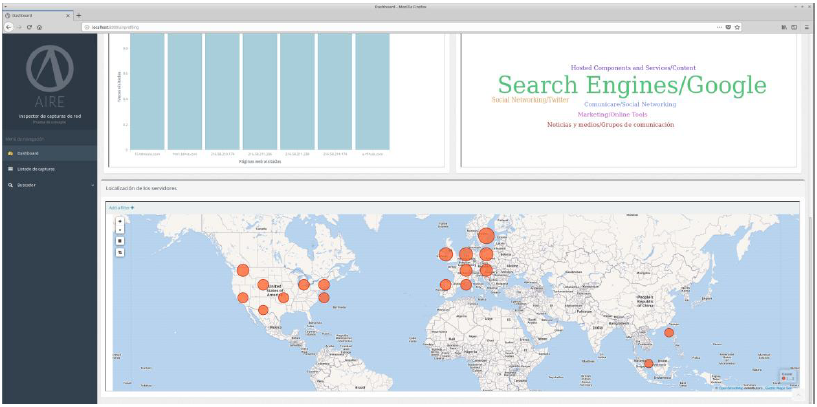
El panel principal incluye varias gráficas que compilan datos de todas las capturas analizadas hasta el momento.
- En la parte superior podemos encontrar el número de dispositivos encontrados en las capturas, y el número de paquetes analizados.

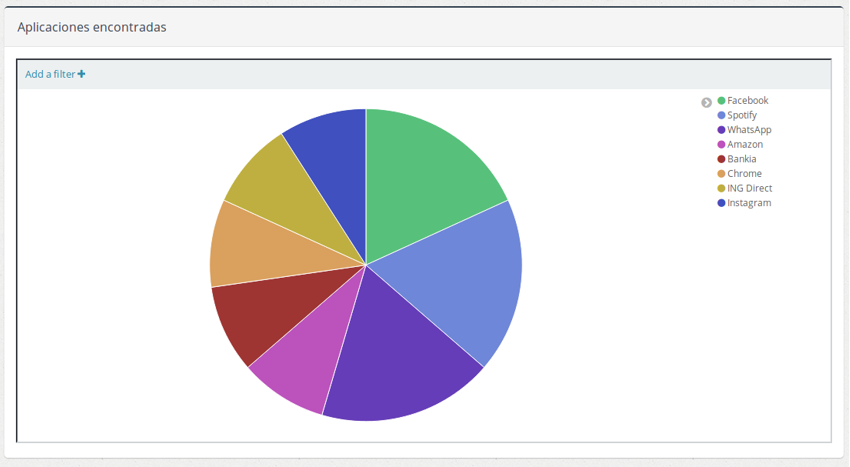
- La gráfica de aplicaciones encontradas muestra el total de aplicaciones detectadas hasta el momento según apariciones.
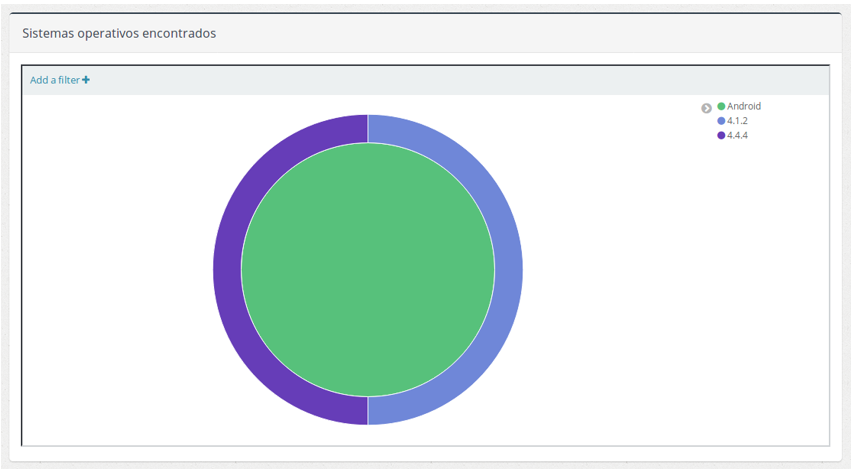
- En la gráfica de sistemas operativos encontrados podemos ver los sistemas operativos que se han detectado en las capturas, agrupados por tipo (Android o IOS).
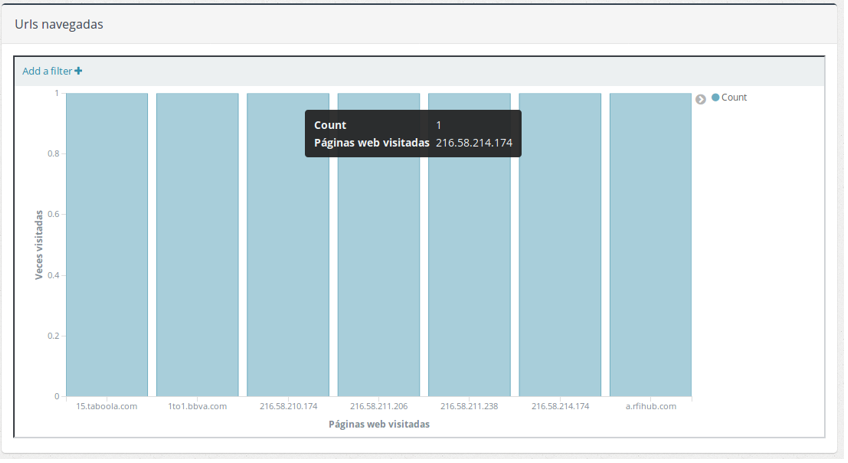
- En la gráfica de Urls navegadas podemos ver las páginas web (o simplemente accesos por HTTP) más visitadas en las capturas.
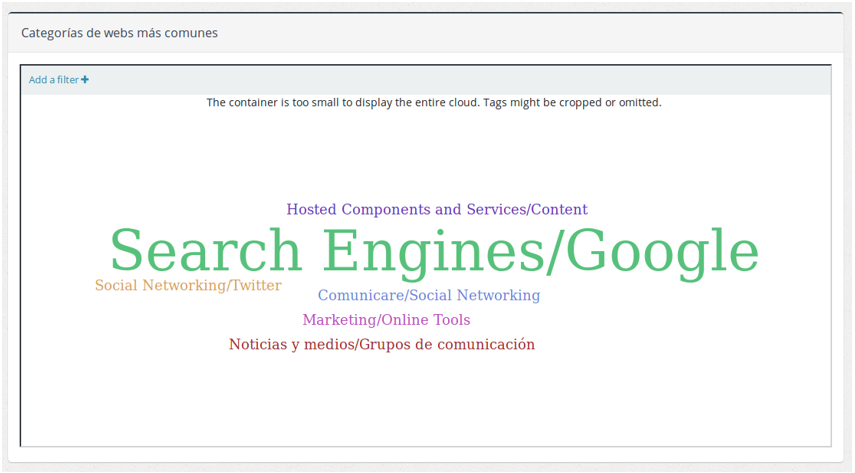
- En las categorías de webs más comunes podemos ver las temáticas más vistas dentro de las capturas en forma de nube de etiquetas.
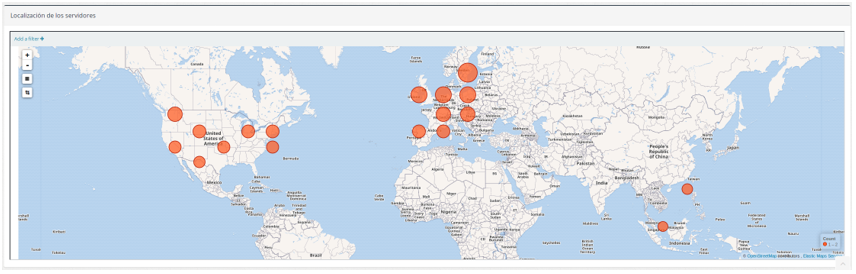
- En el mapa de localización de los servidores podemos ver la ubicación de los servidores accedidos en las capturas y el número de accesos según el tamaño de las marcas.
Listado de capturas
En el listado de capturas podemos ver una lista con datos básicos acerca de las capturas analizadas hasta el momento, como puede ser el dispositivo mayoritario detectado, la fecha y hora de la captura y otros datos más específicos como aplicaciones y páginas web detectadas, direcciones IP accedidas y el explorador web utilizado.
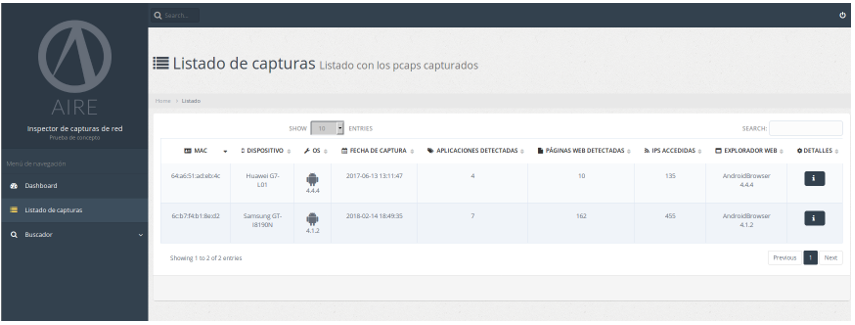
Podemos hacer click en el botón de detalles para ver la página específica de los datos de cada captura.
Detalle de información de la captura
En la página de detalle de las capturas analizadas tenemos tres diferentes pestañas disponibles: General, Timeline y Mapa.
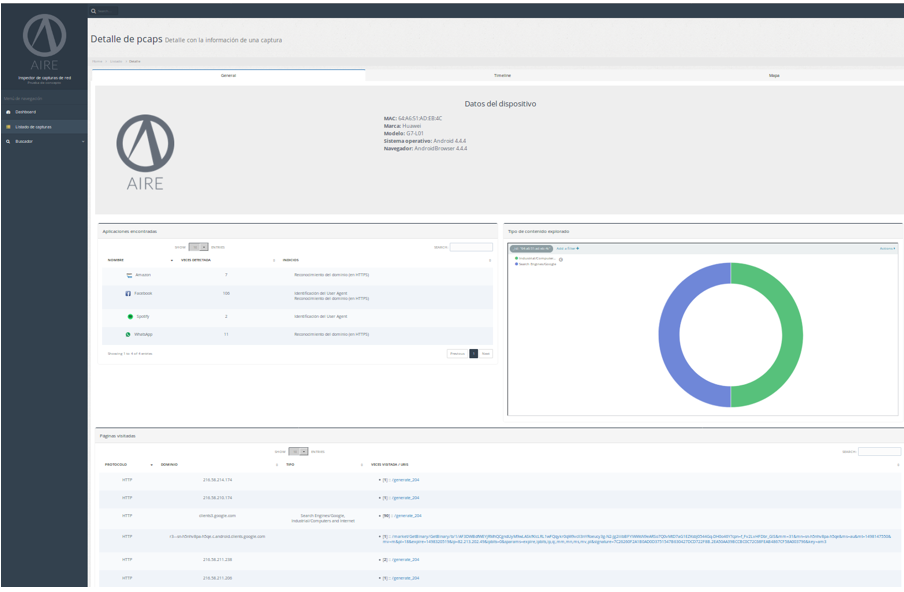
Dentro de la pestaña general podemos ver, de forma parecida al Dashboard, varios elementos y gráficas:
- Arriba tenemos algunos datos básicos acerca del dispositivo del que hemos realizado una captura.

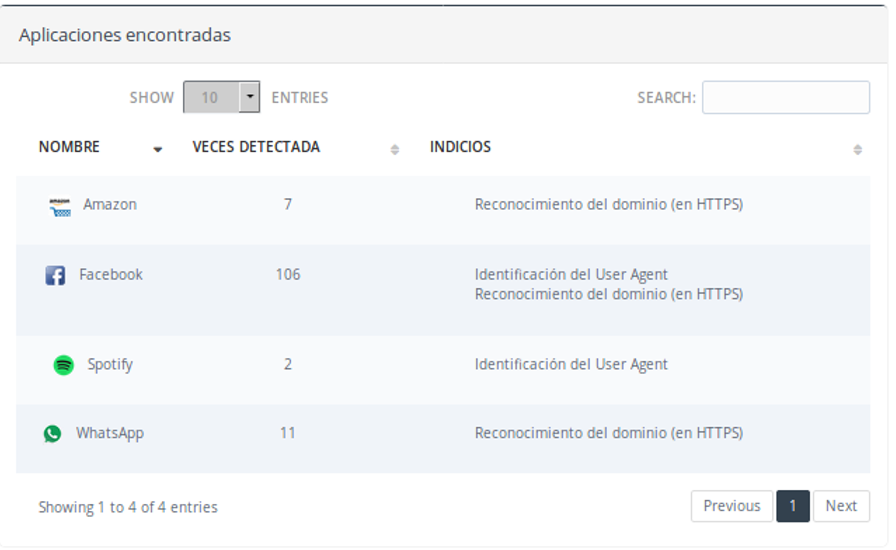
- Tenemos a continuación el panel de aplicaciones encontradas, con una lista de aplicaciones que se han localizado dentro de la captura, las veces que se ha detectado y el tipo de indicio o indicios que han disparado la detección.
- En la gráfica de tipo de contenido explorado veremos las temáticas detectadas en las visitas web extraídas de la captura.

- Por último, podemos ver las páginas visitadas, con una lista de los dominios y URIs visitadas en la captura y el número de accesos a las mismas, así como la temática en caso de detectar alguna.
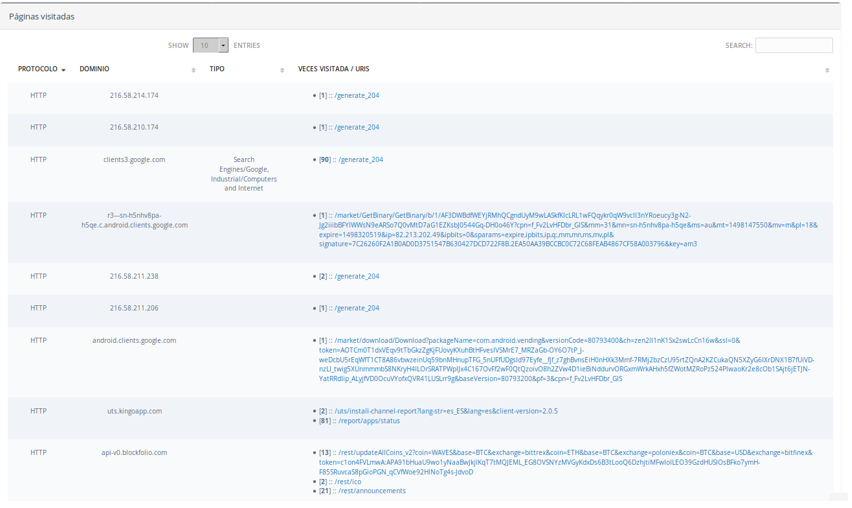
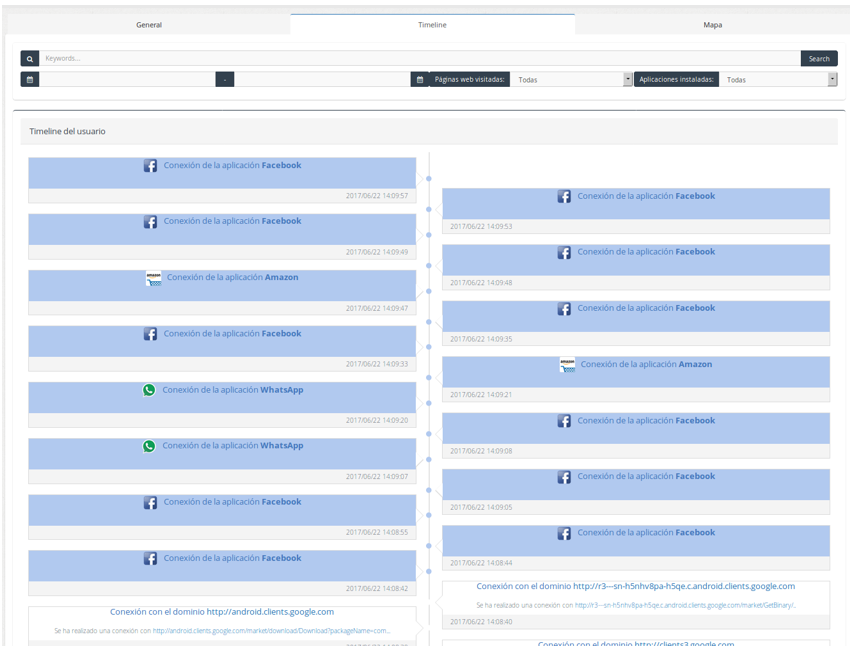
En la pestaña del Timeline podemos ver una línea de tiempo que contiene el momento de la captura en el que se ha detectado una aplicación o bien un acceso web. Podemos usar los diferentes campos del buscador para filtrar la Timeline y mostrar solamente las aplicaciones o dominios accedidos que parezcan relevantes.
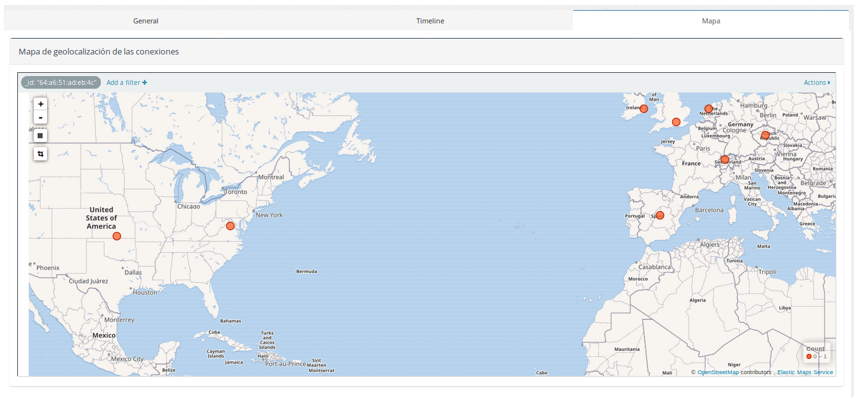
Por último, en la pestaña de mapa podemos ver la geolocalización de los servidores accedidos en la captura, de modo similar al mapa visto en el dashboard.
Buscador
Por último, podemos acceder desde el panel lateral a un buscador que nos permitirá mostrar solamente las capturas que coincidan con unos ciertos criterios de búsqueda que podemos encontrar y modificar en la parte superior.
Podremos buscar las capturas, por ejemplo, en las que se haya detectado una cierta aplicación o que estén en un rango específico de fechas.

Agregar nuevas aplicaciones a la detección
El proyecto se apoya en una serie de ficheros de configuración contenidos en el mismo para realizar la detección de aplicaciones. Estos ficheros se localizan en la dirección parsing/analyzers/data_files desde la raíz del proyecto y pueden editarse con el fin de añadir más aplicaciones que quieran detectarse.
Asimismo, otra dirección relevante para esto es airprofiling/airprofiling/static/img/app_icons, que contiene los iconos de las aplicaciones a detectar, simplemente para que se muestren de forma distintiva en la aplicación.
A la hora de agregar una aplicación a detectar, podemos seguir estos pasos:
- En el fichero de configuración json, podemos encontrar un fichero formateado como JSON. Podemos agregar a la lista que puede verse bajo app_domain nuevos valores, que son el nombre de la aplicación como clave y una lista de los dominios que queramos relacionar con la misma como valor.
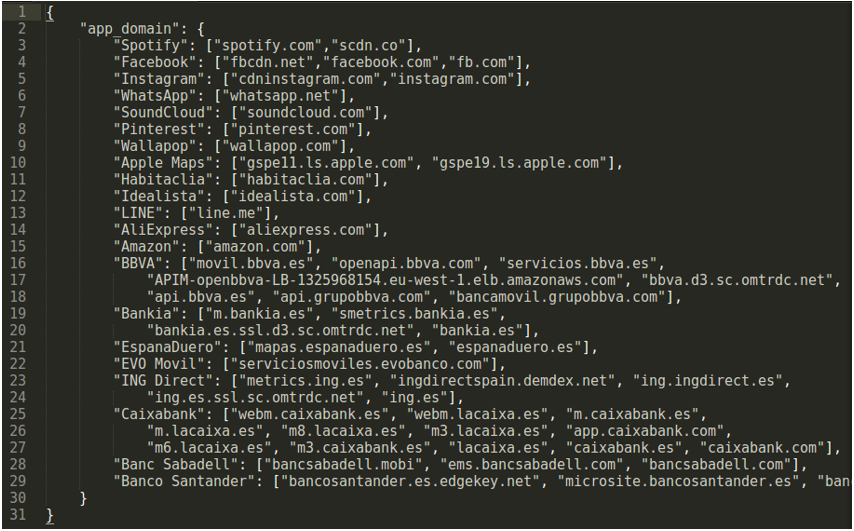
- De forma similar, en el fichero json podemos encontrar en la estructura JSON una lista de aplicaciones a detectar y una palabra contenida en el número de sistema autónomo detectado por la base de datos GeoIP.
Por ejemplo, la aplicación Bankia es reconocida por GeoIP como parte del sistema autónomo AS20748 Bankia S.A. Podemos introducir simplemente la palabra Bankia, contenida en el nombre del AS.
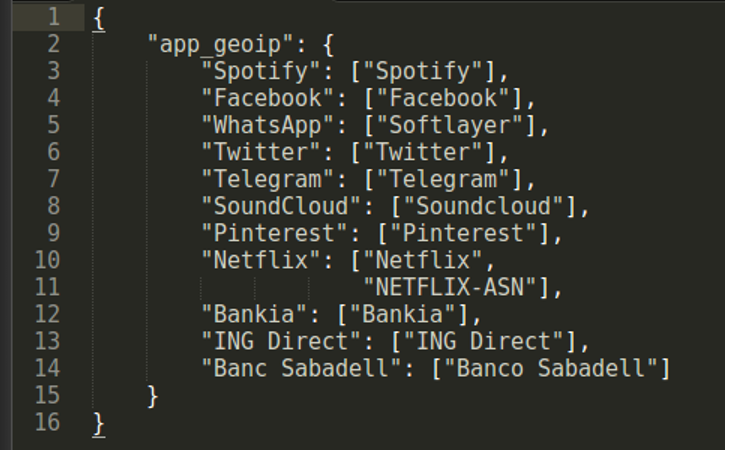
- En el fichero de configuración json¸ de forma parecida, podemos introducir una palabra contenida en el agente de usuario que queramos relacionar con la aplicación.

- Por último, en la carpeta airprofiling/airprofiling/static/img/app_icons anteriormente nombrada podemos introducir una imagen en formato PNG cuyo nombre será el de la aplicación que hemos utilizado al agregarla en los ficheros de configuración en minúsculas. El sistema la relacionará de forma automática.

Hasta aquí hemos llegado señoras y señores. Una entrada un poco densa acerca de la instalación y el funcionamiento, pero que era a mi parecer necesaria para que podáis entender el funcionamiento del mismo 🙂
Muchas gracias por vuestras lecturas y esperamos que os guste y os sirva para aprender. Un saludo!!
Un comentario en «AIRE (II) – Instalación y uso del sistema de análisis»
Los comentarios están cerrados.