
Buenos días a todos, es un placer volver a estar por aquí de nuevo. No sabéis la alegría que me ha dado entrar al blog y darme cuenta de que mi cuenta seguía estando en el grupo de colaboradores. Aún no me han echado. Voy marcando días en mi pared como un náufrago esperando a ser rescatado. Esta vez no voy a entrar en detalles de mi tardanza ni a dar explicaciones de mi ausencia, no tengo como decorar este árbol de navidad que desde que se compró se sabía estaba defectuoso. Mi última entrada fue publicada el 22 de Noviembre de 2017, juzguen ustedes mismos.
No, en serio, disponen de unos segundos para ponerme a parir. Aprovechen para desahogarse. Ya me tienen acostumbrado por el grupo de Telegram a ser el sparring oficial.
¿No me creen? Aquí tiene las pruebas, señoría.
En esto último puede que tuviesen parte de razón.
Love is in the air, decían.
Bueno, vamos al lío. Llevo un tiempo en el mundillo del aprendizaje automático. Digamos que estoy dando mis primeros pasitos. Como Neil Amstrong pisando la Luna. «Es un pequeño paso para un hombre, pero un gran salto para la humanidad». Yo sabía que tarde o temprano tenía que acabar cayendo aquí. Si estaba claro, me lo repitieron miles de veces durante años y yo me negaba porque no quería ver la realidad, no quería creer que tendría que acabar entrenando máquinas. De eso tiene parte de culpa la película «Real Steel«, pésima. La otra parte de culpa, en este caso, de que empezase a interesarme por el aprendizaje automático fue de un compañero y amigo que conocí hace poquito por mi nueva aventura. Es increíble verle hablar de inteligencia artificial, de aprendizaje automático o de deep learning. Le brillan los ojos, prometido. No he visto nunca a nadie disfrutar tanto explicando conceptos que solo él conoce. Estoy seguro de que la primera vez que estuvimos charlando sobre estos temas mi cara era un auténtico poema y sin embargo lo disfruté como si fuera un experto más debido a las ganas que trasmitía.
Yo quería encontrar esa sensación. Y vaya si la encontré.
¿Recuerdan ustedes su primer amor? ¿Su primer beso? Se trata de uno de esos momentos que se te quedan grabados en la memoria por las sensaciones que te producen. Lo que sientes cuando estás en ese momento es bestial. Así me sentí yo. Bueno, aquí estoy exagerando. Digamos que aprender desde cero los entresijos de la inteligencia artificial, hacer mis primeras pruebas de aprendizaje automático…fue como un niño abriendo sus juguetes nuevos de navidades. Sabes lo que has pedido y sabes que, a menos que te hayas portado muy mal, el 25 de Diciembre te levantarás corriendo de la cama como si la vida te fuese en ello, bajarás a toda prisa las escaleras que conducen a ese defectuoso árbol de navidad que tus padres compraron y que apenas puede sujetar unos pocos adornos y te encontrarás con lo que ponía en la carta. ESA SENSACIÓN. Como en una nube. Como ese primer sorbo a un Old Fashioned cada vez que vuelvo a mi tierra o la primera vez que escuché «Espíritu Olímpico» de los Planetas. De nuevo esa sensación.
En definitiva, amores correspondidos.
Como los protagonistas de la imagen destacada, Bart y Annie en Gun Crazy. Nacidos para estar juntos y robar bancos.
Me encantaría decir que es una sensación similar a las dos primeras descritas, pero estaría mintiendo.
Así que ahí estaba yo, despidiéndome de mi compañero con sus mismos ojos brillantes y corriendo para casa.
¿Dónde vas Juan?

A lo largo de esta entrada voy a tratar de explicar, de la mejor manera posible, lo que he aprendido a grandes rasgos del aprendizaje automático. Veremos una parte más teórica (aunque breve, espero) que nos permitirá poder entrar en materia más adelante con unas pruebas sobre algunos ejemplos prácticos.
Ritmo.
Ésta primera está dedicada a mi amigo Belane, que siempre confió en mi buen criterio para la música y me convenció de que era una parte vital en cualquiera entrada de blog.
Lo primero sería definir qué es aprendizaje automático, recuerden que las grandes mansiones siempre se empiezan por abajo. Aunque yo siempre he sido más de cabaña en algún rincón perdido.
El aprendizaje automático (o machine learning) es una de las ramas de la Inteligencia Artificial. Se encarga de desarrollar algoritmos capaces de generalizar comportamientos y reconocer patrones a partir de datos e información proporcionada en forma de ejemplos. El objetivo es que el ordenador aprenda a identificar dichos patrones y sea capaz de reaccionar correctamente ante ellos.

Se trata, por tanto, de un proceso inductivo del conocimiento, es decir, un método que permite obtener por generalización un enunciado general a partir de enunciados que describen casos particulares.
Predecir comportamiento futuro a partir de lo ocurrido en el pasado.
¿Les suena esta frase?
Algunos de los campos o aplicaciones del aprendizaje automático serían los siguientes:
- Detección de fraudes.
- Créditos de bancos.
- Búsquedas web.
- Reconocimiento de voz.
- Reconocimiento facial.
- Recomendación de productos.
- Filtrado de correo spam.
- Diseño y descubrimiento de nuevos medicamentos.
- Puntuación automática en exámenes, redacciones, etc.
- Detección de ciberataques.
- Mejora en los sistemas IDS aprendiendo de los ataques que reciben.
- Predicción de crímenes.
- Muchos más.
Lo siguiente será ver los tipos de algoritmos que usa el aprendizaje automático, como por ejemplo:
- Aprendizaje supervisado (supervised learning).
- Aprendizaje no supervisado (unsupervised learning).
Existen algunos más como el aprendizaje semisupervisado o el aprendizaje por refuerzo pero que no cubriremos en esta entrada. Cada uno de estos se aplicará a problemas concretos en función de su utilidad para resolverlos.
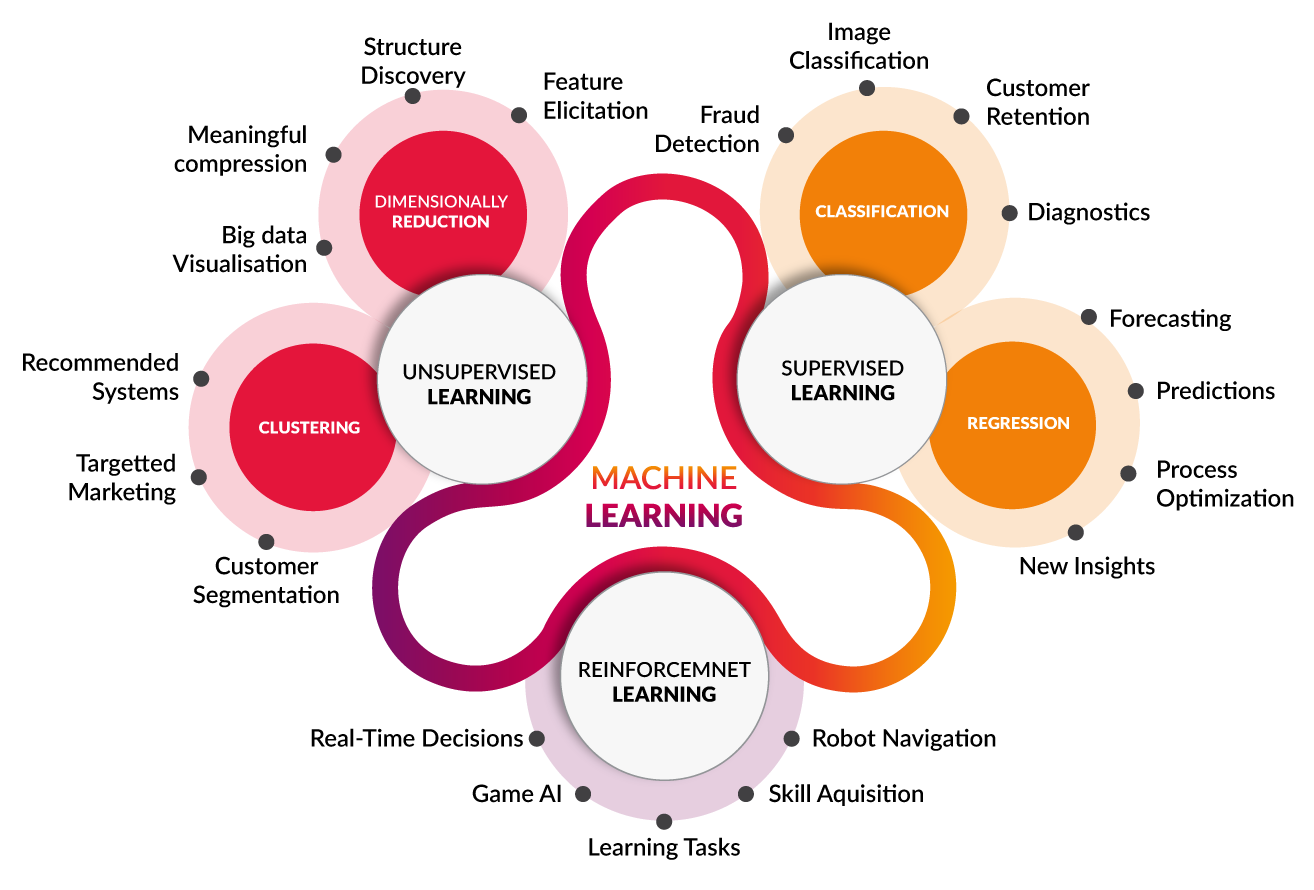
El aprendizaje supervisado es un tipo de algoritmo que produce una función que establece una correspondencia entre las entradas y las salidas deseadas del sistema. Un ejemplo de este tipo de algoritmo es el problema de clasificación, donde el sistema de aprendizaje trata de etiquetar (clasificar) una serie de vectores utilizando una entre varias categorías (clases). La base de conocimiento del sistema está formada por ejemplos de etiquetados anteriores. Este tipo de aprendizaje puede llegar a ser muy útil en problemas de investigación biológica, biología computacional y bioinformática.
Un ejemplo muy concreto de problema de clasificación es diferenciar, por ejemplo, entre naranjas y manzanas. Parece un problema muy sencillo, ¿pero cómo puede un ordenador clasificar si una imagen es una manzana o una naranja?
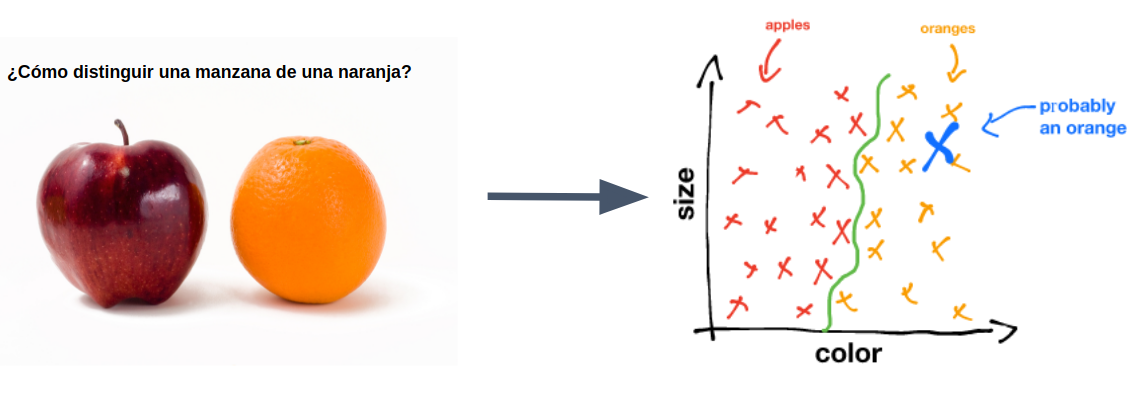 Por ejemplo, creando un problema de clasificación binario (dos posibles etiquetas, naranja o manzana). Para esa clasificación nos basaremos en una larga colección de ejemplos etiquetados previamente en los que guardaremos el tamaño, el color y la etiqueta correspondiente a esas dos características. El algoritmo de clasificación, dados dos nuevos valores para el tamaño y color de un objeto, podrá identificar la probabilidad con la que ese objeto es una manzana o es una naranja.
Por ejemplo, creando un problema de clasificación binario (dos posibles etiquetas, naranja o manzana). Para esa clasificación nos basaremos en una larga colección de ejemplos etiquetados previamente en los que guardaremos el tamaño, el color y la etiqueta correspondiente a esas dos características. El algoritmo de clasificación, dados dos nuevos valores para el tamaño y color de un objeto, podrá identificar la probabilidad con la que ese objeto es una manzana o es una naranja.
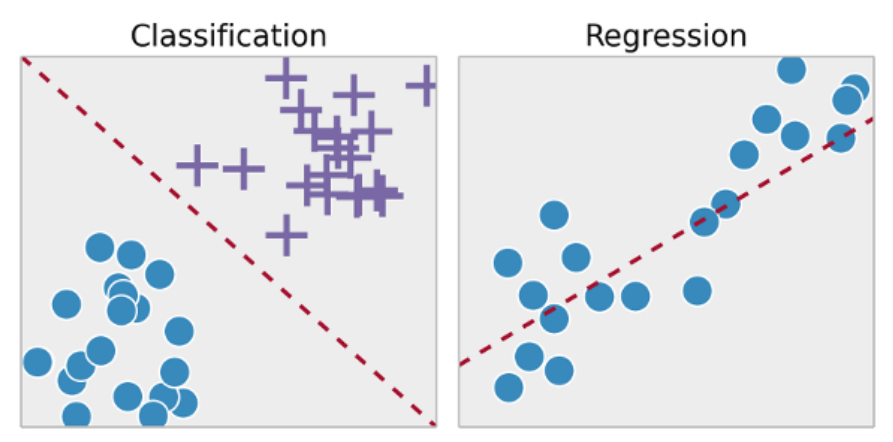
Por otra parte, el aprendizaje no supervisado busca modelar sobre un conjunto de ejemplos formado tan sólo por entradas al sistema. No se tiene información sobre las categorías de esos ejemplos. Por lo tanto, en este caso, el sistema tiene que ser capaz de reconocer patrones para poder etiquetar las nuevas entradas. En este caso, el problema más conocido es el de «clustering».
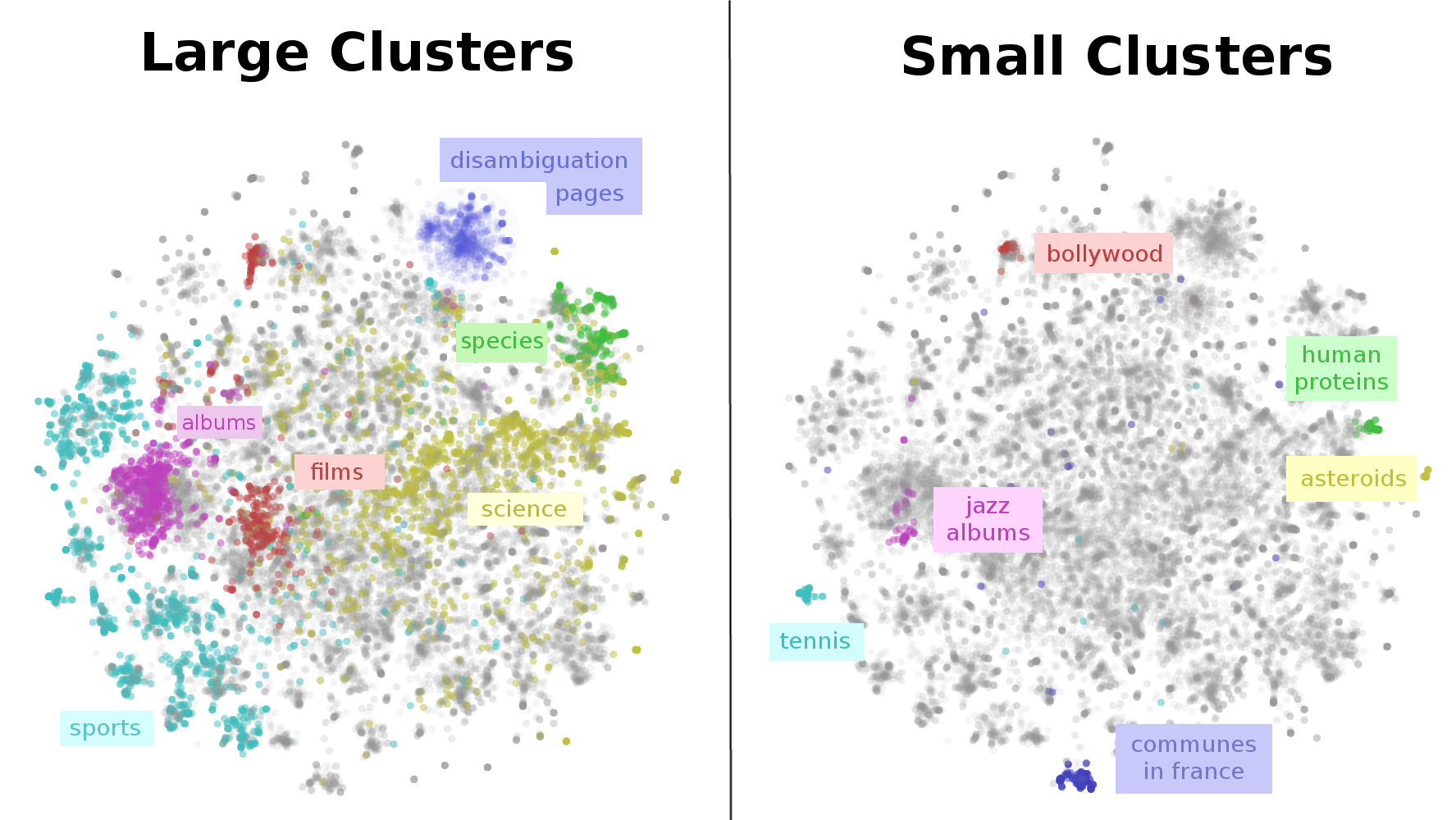
Clustering es el proceso por el cual, a partir de unos datos no etiquetados o categorizados, somos capaces de reconocer diferentes patrones que nos permiten etiquetar las nuevas entradas. Por ejemplo, en el conjunto de datos que vemos en la imagen de abajo, podemos distinguir clusters o grupos más grandes representando categorías generales (especies, albums, películas, ciencias, deportes,…) y otros representando grupos más pequeños y concretos (humans, jazz, hollywood, asteroids, tennis,…) de manera que, cuando recibamos una nueva entrada, sepamos categorizarla en función de la posición en la que se dibuje en nuestro gráfico.
Un ejemplo muy concreto de problema de clustering podría ser la búsqueda de una audiencia concreta para un determinado producto que queremos sacar al mercado. Como se indica en la imagen de abajo, se buscaría identificar los diferentes perfiles de los usuarios de nuestra página web y enfocar la venta de nuestro nuevo producto a aquellos que cumplan ciertos requisitos (como número de visitas, tiempo que invierten en la página web, etc.).
Os presento a Amazon.
¿Cómo vamos de música? Por favor, no quiero que les falte de nada a mis invitados.
Para dichos tipos de aprendizaje se utilizan modelos o algoritmos que serán los que entrenaremos con nuestros datos. A continuación mencionaré algunos de los algoritmos más conocidos y utilizados tanto para el aprendizaje supervisado como para el aprendizaje no supervisado. Veremos alguno de estos algoritmos en la parte práctica.
Clasificaremos los algoritmos más conocidos del aprendizaje supervisado en dos grupos, dependiendo del tipo de etiqueta que tengan los datos:
- Si las etiquetas son categorías o valores discretos
- Árboles de decisión.
- KNN (K-Nearest Neighbors)
- Regresión logística
- Naive-Bayes
- SVC
- SVM
- Si las etiquetas son valores continuos
- Regresión SVR
- Lineal
- Polinomial
- Árboles de decisión
- Random forests
- Regresión SVR
En el caso de los algoritmos más conocidos del aprendizaje no supervisado haremos lo mismo, distinguir en función de si los grupos que hacemos se basan en etiquetas de categorías o de valores continuos.
- Si las etiquetas son categorías o valores discretos
- Análisis por asociación
- A priori.
- FP-Growth
- Modelo de Markov
- Análisis por asociación
- Si las etiquetas son valores continuos
- Clustering y reducir dimensiones
- SVD
- PCA
- K-Means
- Clustering y reducir dimensiones
Vamos a ver algunos de ellos con más detalle.
Support Vector Machines
Support Vector Machines o SVMs son un conjunto de métodos o modelos de aprendizaje automático supervisado usados para clasificación, regresión o detección de valores atípicos.
Las ventajas de este tipo de modelos son las siguientes:
- Efectivos en espacios o problemas con muchas dimensiones.
- Efectivos también en el caso de que el número de dimensiones sea incluso mayor que el número de muestras.
- Utiliza un subconjunto de los datos de entrenamiento en la función de decisión siendo más eficiente en memoria.
- Es versátil, puede usa diferentes funciones de decisión.
Intuitivamente, una SVM es un modelo que representa a los puntos de muestra en el espacio, separando las clases a 2 espacios lo más amplios posibles mediante un hiperplano de separación definido como el vector entre los 2 puntos, de las 2 clases, más cercanos al que se llama vector soporte.
Cuando las nuevas muestras se ponen en correspondencia con dicho modelo, en función de los espacios a los que pertenezcan, pueden ser clasificadas a una o la otra clase.
Más formalmente, una SVM construye un hiperplano o conjunto de hiperplanos en un espacio de dimensionalidad muy alta (o incluso infinita) que puede ser utilizado en problemas de clasificación o regresión. Una buena separación entre las clases permitirá una clasificación correcta.
Dentro de los SVM podemos encontrar:
- SVC, NuSVC o LinearSVC: Destinados a los problemas de clasificación de una o más clases.
- SVR, NuSVR y LinearSVR: Destinados a los problemas de regresión.
Dado el problema de aprendizaje automático típico de Iris en el cual se cuantifica la variación morfológica del Iris con las flores de tres especies relacionadas tenemos los siguientes resultados:
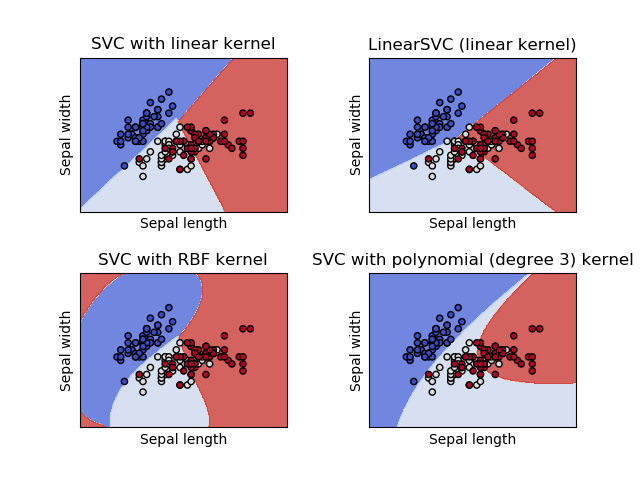
En dicho conjunto de datos se miden cuatro rasgos de cada muestra: longitud y anchura de sépalos y pétalos. Cada una de las tres especies estudiadas se representa por un color diferente en la gráfica superior.
KNN (K-Nearest Neighbors)
La clasificación basada en los vecinos es un tipo de aprendizaje basado en instancias o «no generalizador»: no intenta construir un modelo interno general, sino que simplemente almacena las instancias de los datos del entrenamiento. La clasificación se calcula a partir de un voto por mayoría simple de los vecinos más cercanos de cada punto: se asigna un punto de consulta a la clase de datos que tiene más representantes dentro de los vecinos más cercanos del punto.
Y es que tenemos que querer a nuestros vecinos y vecinas.

A veces es una buena idea permitir que ellos nos quieran a nosotros también.
La representación del modelo en el caso del KNN es el conjunto de datos de entrenamiento al completo. Así de simple. KNN es un modelo que guarda estos datos al completo, de manera que no es necesario aprender.
Como el conjunto de datos de entrenamiento se guarda al completo es importante saber como de consistente es nuestro conjunto puesto que tal vez convenga invertir más tiempo de depurarlo o actualizarlo de manera que los nuevos datos sean realmente relevantes y no contengan errores.
Por tanto, como hemos dicho, KNN hace predicciones usando directamente el conjunto de datos de entrenamiento. Es decir, para una nueva instancia se busca en todo el conjunto de datos las «K» instancias más cercanos (es decir, sus vecinos) de manera que la etiqueta que finalmente tenga nuestra nueva instancia esté en relación con la de sus vecinos.
Vamos a fijarnos en la gráfica inferior.
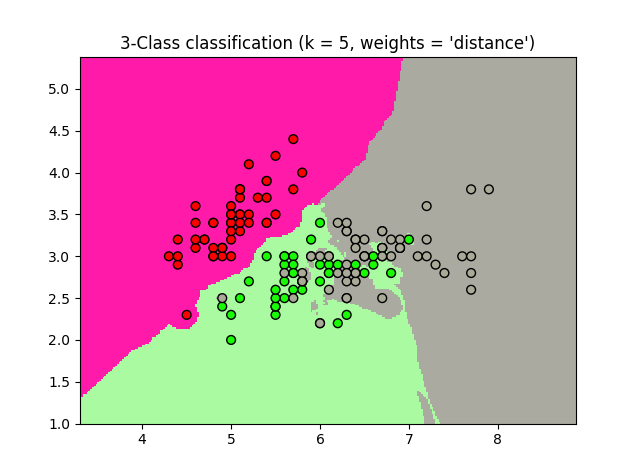 En esta gráfica se representa un conjunto de datos, que, para dos características o «features» dibujadas en los ejes coloca los puntos en una zona determinada. En este caso, tenemos 3 etiquetas (3 posibles clases que vienen definidas por su color, rojo, verde o gris).
En esta gráfica se representa un conjunto de datos, que, para dos características o «features» dibujadas en los ejes coloca los puntos en una zona determinada. En este caso, tenemos 3 etiquetas (3 posibles clases que vienen definidas por su color, rojo, verde o gris).
Pensemos en nuevo dato, cuyas características o features son:
- Valor para el eje x = 6
- Valor para el eje y = 2
Nuestro nuevo punto, en la gráfica, estaría dentro de la zona verde. Por tanto, su etiqueta o clase sería la correspondiente a ese color.
¿Por qué?
Si os fijáis, el punto quedaría cerca de tres puntos (dos verdes y uno gris). Puesto que nuestro modelo es un 3NN (el número de vecinos en los que nos fijaremos es 3) y de esos tres vecinos hay mayoría de verdes, su etiqueta sería la misma que la de estos.
Existen muchas formas de calcular las distancias entre los puntos, las más conocidas son la distancia Euclidiana, la distancia de Hamming, la de Manhattan (como el cocktail) o la distancia de Minkowski.
Para concluir la entrada y tratar de llevar estos conceptos teóricos a la práctica pasaremos a usar un notebook de Jupyter donde poder ir viendo como utilizar el aprendizaje automático para resolver un problema concreto.
Queremos utilizar los datos de los crímenes de los últimos años de una ciudad como San Francisco para tratar de predecir el tipo de crimen que ha ocurrido a partir de unos datos dados como la localización del crimen, el departamento que se encargó de dicho crimen, etc.
Esta parte práctica ha sido realizada utilizando Python como lenguaje de programación y algunas de las siguientes librerías o paquetes del mismo:

Podéis encontrar el notebook (con las explicaciones pertinentes) en mi repositorio de Github:
https://github.com/juanvelascogomez/sf_crime_sklearn
Hasta aquí llega esta entrada, ustedes revisen si tienen curiosidad esa parte práctica que yo mientras voy a Telegram a responder a esos compañeros que tanto se meten conmigo. Si no vuelvo a escribir será que finalmente me vencieron. Recuérdenme con cariño.
Por mi parte, recordaros como siempre que podéis contactar conmigo vía twitter (@juanvelasc0) y si me queréis conocer algo más, podéis pillarme en los diferentes bares y restaurantes de vuestra zona (a veces hasta altas horas de la mañana) y aunque ya no suelo ser un habitual, también por algunas CON’s y eventos que se realizan por España.
Ahora que empieza a salir el sol y comienza a oler a verano les animo a marchar en busca de estas aventuras, que aunque muchas veces son pasajeras, dejan su huella.
Por si me despisto y tardo más en llegar, pasen un buen verano y busquen su historia de amor correspondida. Yo haré lo propio.
Recuerdos para todos,
HoldenV
4 comentarios en «Aprendizaje automático y amores correspondidos»
Hola, el link para descargar el dataset, archivos csv, que mencionas en tu codigo?
Un saludo,
Hola Víctor, te envío aquí los enlaces y actualizaré el repositorio de Github con ellos.
Test: https://mega.nz/#!2hNBRK7S!RkRVg7J3OmaZNONy3VaCIBbkwD4WKokTIfqChd95NGw
Entrenamiento: https://mega.nz/#!G50hkLLA!JrwIhx8NsDWaMYRVXKUBc_Chnfur1j7MLiBYS7NUUeo
Un saludo
Gracias por esta introducción al aprendizaje automático algo mas detallada que la ponencia junto con tu compañero aquí en Salamanca, siempre había tenido ganas de asistir a un evento de este estilo y que mejor ocasión que está para verla «in situ».
Gracias de nuevo por el evento 🙂
Gracias a ti por tus comentarios, una pena no poder resolver dudas o charlar después de las jornadas. Por suerte, sabes que nos puedes encontrar en las diferentes redes sociales para lo que necesites 🙂
Un saludo
Los comentarios están cerrados.