Buenas a todos, tenía ganas de escribir sobre Reversing y poder compartir a toda la Comunidad e ir aprendiendo poco a poco entre todos. Mi idea es escribir bastantes entradas al principio usando código escrito en C o C++, compilándolo y con la herramienta radare2 reversear el binario. Esta tool la pueden encontrar aquí: https://github.com/radare/radare2
Una buena fuente de documentación para el uso de esta tool la encontraréis aquí: https://radare.gitbooks.io/radare2book/content/
Además lo tenemos traducido al castellano gracias al amigo de SoftDat de CrackSLatinoS, gracias por tu aporte 😉
Indice
Introducción al Reversing – 0x00 Introducción
Introducción al Reversing – 0x01 Introducción
Introducción al Reversing- 0x02 Instrucciones básicas de x86 Intel
Introducción al Reversing – 0x03 Hardcoded1.exe y crackme.exe
Introducción al Reversing – 0x04 crackmeeasy.exe
Introducción al Reversing – 0x05 Reverser.exe
Introducción al Reversing – 0x06 Lotto
Introducción al Reversing – 0x07 Use After Free
Introducción al Reversing – 0x08 Memcpy
Introducción al Reversing – 0x09 Ganando shell gracias a Brainfuck
Introducción al Reversing – 0x0A Hack.lu CTF 2018, baby reverse
Introducción al Reversing – 0x0B Shellcode básica
Introducción al Reversing – 0xC Instrucciones SIMD
Introducción al Reversing – 0xD Análisis de código con Ghidra
Introducción al Reversing – 0xE PE Injection
Introducción al Reversing – 0xF Keylogger
Introducción al Reversing – 0x10 Baby’s Flare-On
Introducción al Reversing – 0x11 Algoritmo básico de descifrado de una función
Introducción
El Reversing, a grandes rasgos es averiguar desde un «producto» ya finalizado su proceso inverso. En el caso de la informática desde un binario o software conocer su código fuente, interpretando el lenguaje de alto nivel que se utilizo en el desarrollo del programa. Conociendo el funcionamiento de la CPU un hacker será capaz de obtener el código fuente a partir del binario.
El lenguaje ensamblador x86 es la familia de los lenguajes ensambladores para los procesadores de la familia x86, siendo el procesador Intel 8086 el primero. Usa una serie de mnemotécnicos para representar las operaciones fundamentales que el procesador puede realizar. El x86 tiene 2 vertientes diferentes en cuanto a su sintaxis de programación: sintaxis Intel, usada en sus inicios para la documentación de la plataforma x86, y sintaxis AT&T . La sintaxis Intel es la dominante en la plataforma Windows. Nosotros en las entradas usaremos la sintaxis Intel.
Vemos las primeras instrucciones que nos podemos encontrar en una función main, en lenguaje ensamblador. Más adelante en esta entrada profundizaremos y realizaremos un análisis estático con radare2.

Cada Byte corresponden 8 bits y puede interpretarse como 2 dígitos hexadecimales. En la primera instrucción el «55» en hexadecimal corresponde a 1 Byte, y cada Byte tiene asignada una dirección de memoria.
En la parte de la izquierda los números hexadecimales corresponden a las direcciones de memoria. Los Bytes de las instrucciones del lenguaje máquina en la parte central deben de estar almacenados en alguna parte siendo en la memoria, numerados con direcciones. Estos Bytes en hexadecimal corresponden a las instrucciones en lenguaje máquina para los procesadores de 32 bits, x86. Son representaciones del sistema binario que entiende la CPU, es decir algo como por ejemplo esto 1010110110… El sistema hexadecimal usa base 16, del 0 al 9 y del A a la F para representar los valores entre 10 y 15.
La CPU puede acceder a cada Byte por su dirección de memoria y así obtener las instrucciones de código máquina que componen el programa compilado. Como podéis observar en la segunda instrucción «Mov» vemos 2 Bytes y cada una de ellos en una dirección de memoria diferente (0x08048405 y 0x08048406).
Existe una relación estrecha entre el lenguaje ensamblador y el lenguaje máquina instrucción por instrucción, que le diferencia de los lenguajes de alto nivel o compilados. Por tanto, el lenguaje ensamblador es una representación de las instrucciones del lenguaje maquina que se envían al procesador. Cada instrucción del x86 está representada por un mnemotécnico, que traduce directamente a una serie de bytes la representación de la instrucción, llamada código de operación. Por ejemplo, la instrucción NOP se codifica como 0x90 en hexadecimal.
Las instrucciones hacen uso de los registros del procesador para poder realizar una serie de acciones como mover datos o direcciones de memoria, o realizar operaciones aritméticas o lógicas.
Estos registros son:
- EAX,EBX,ECX,EDX: Son registros de propósito general. Acumulador, base, contador y datos respectivamente. Pueden guardar tanto datos como direcciones.
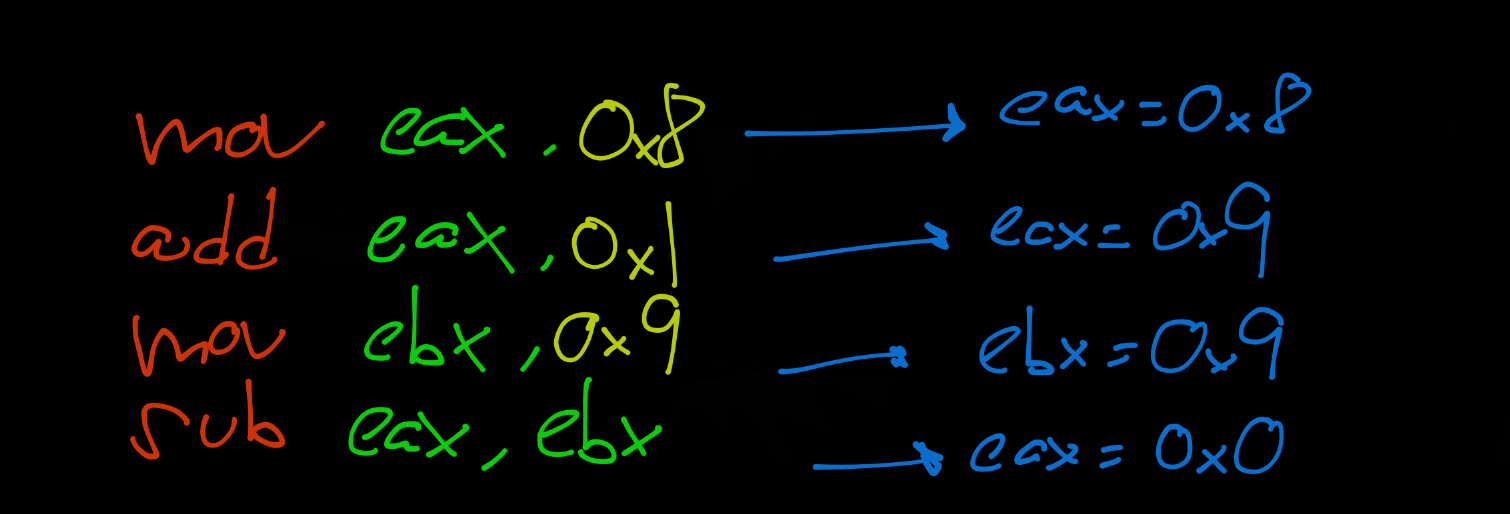
La instrucción MOV: Nos permite mover contenido o direcciones de memoria del origen a destino, siguiendo esta estructura mov dest,orig. ADD permite sumar quedándose almacenado el resultado en destino . SUB es igual pero en resta.
- EBP,ESP: Son registros puntero de base y de pila. ESP(Extended Stack Pointer) es el puntero actual del stack o pila. EBP es la actual base del marco de pila, se usa para hacer referencia en las instrucciones de una función las variables locales.
- EIP: Es el puntero de registro de la siguiente instrucción a ejecutar.

- EDI y ESI. Punteros de destino y origen.
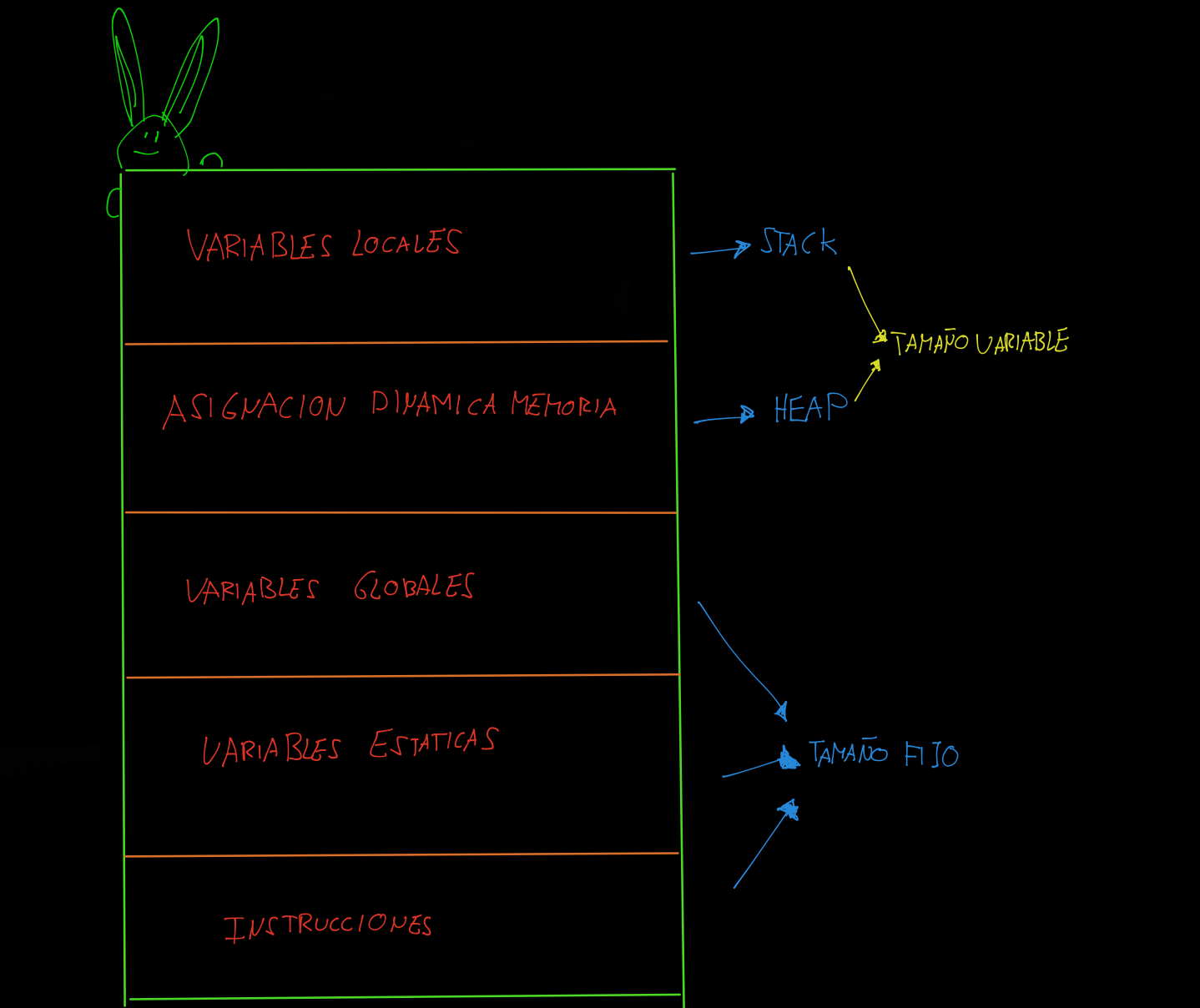
Memoria asignada en un programa C
Se divide en texto, datos, bss, heap y stack.
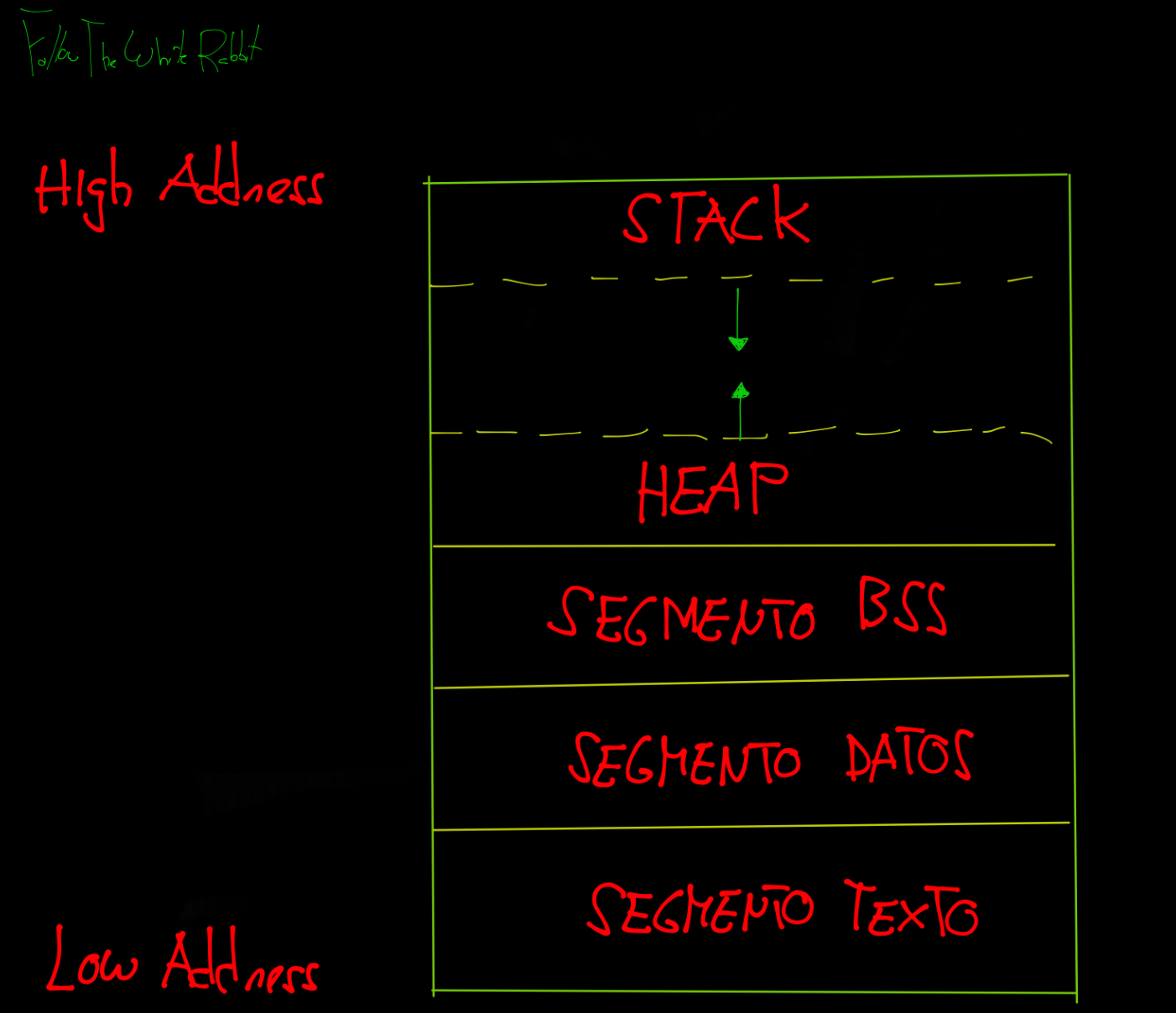
El segmento de texto contiene el código máquina del programa compilado, donde se encuentran las instrucciones ensambladas. Incluye todas las funciones del programa, y su ejecución no es lineal incluyendo los diferentes saltos condicionales debido a las estructuras de control. Este segmento tiene un tamaño fijo. El segmento de texto de un archivo de objeto ejecutable es a menudo segmento de sólo lectura que impide que el programa se modifique accidentalmente y no almacena variables, solo código. De ahí el nombre también de segmento de código.
El segmento de datos almacena los datos del programa. Estos datos podrían ser en forma de variables inicializadas o no inicializadas (segmento bss), y podrían ser locales o globales. El bss sus variables se inicializan a cero o no tienen inicialización explícita en el código fuente. Tiene también un tamaño fijo, pero puede ser segmento de escritura a diferencia del segmento de texto, ya que el valor de las variables pueden modificarse en tiempo de ejecución.
Vamos a ver un ejemplo sencillo en lenguaje C de base.
Ahora con size, vemos el espacio reservado en los segmentos.

Declaramos una variable estática sin inicializar dentro de la función main y vemos como aumenta el tamaño del bss.
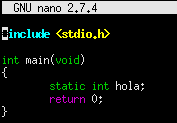
![]()
Y ahora declaramos una variable incializandola, para ver como el tamaño del segmento data varía.
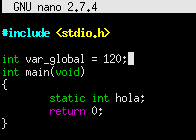
![]()
Por tanto las variables globales y estáticas están almacenadas en un tamaño fijo de la memoria.
El segmento Heap no es administrada automáticamente, es una tarea manual controlado por el desarrollador. No tiene tamaño fijo y crece hacia las direcciones más altas de memoria en contraposición al Stack. La asignación de memoria en el Heap se logra mediante las funciones de C, malloc(), calloc() o new en el caso de C++. Las variables almacenadas son globales.
Un ejemplo de asignación de espacio dinámico de memoria a la variable x, en el segmento heap. Liberación del espacio con la función free().
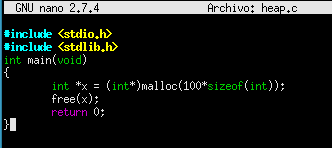
La función malloc() reserva un determinado bloque de memoria dado por un tamaño, y devuelve un puntero «*x».
El segmento Stack almacena temporalmente argumentos y variables locales a la llamada de una función de nuestro programa.
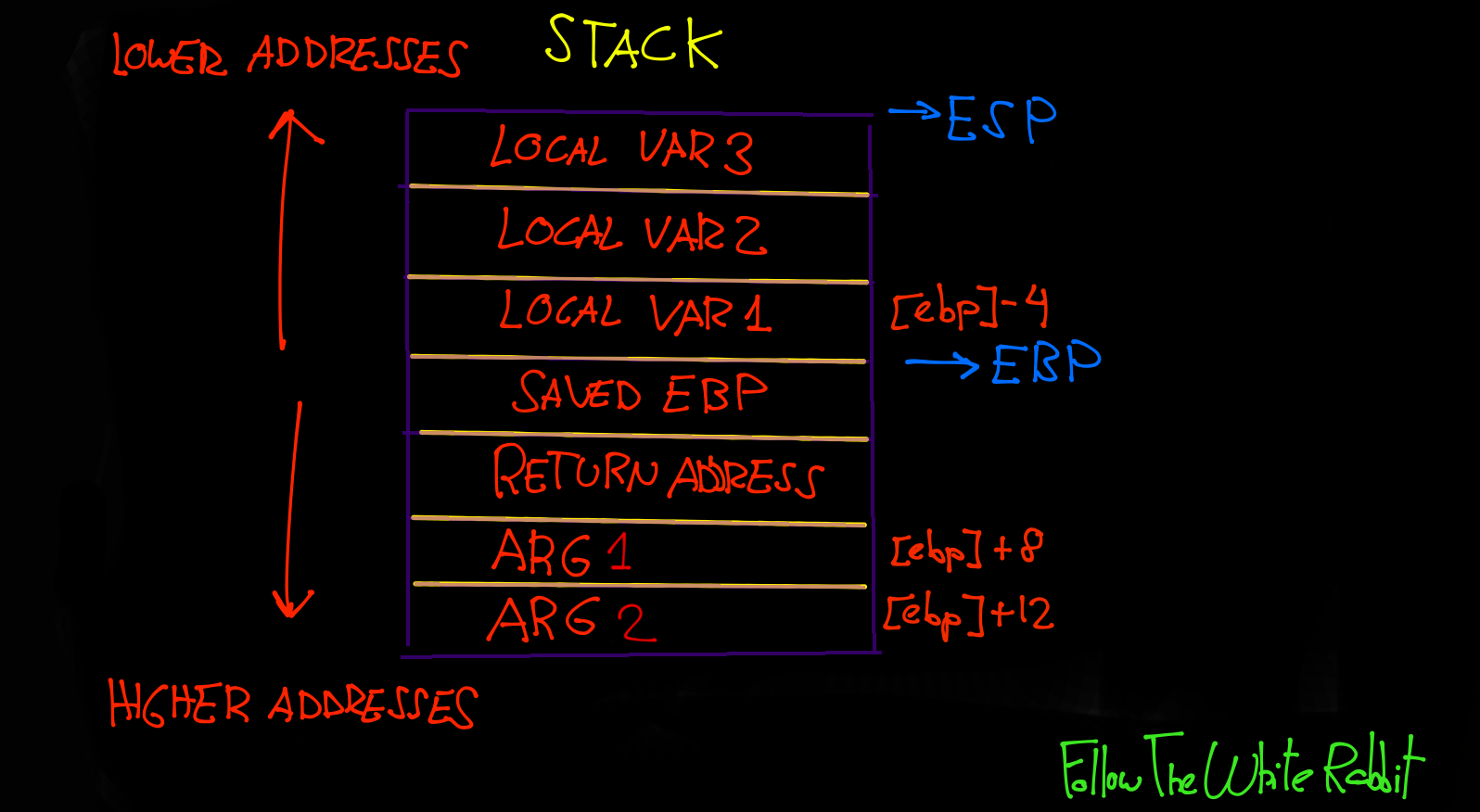
Cuando se llama a una función, se deja un espacio en la pila para las variables locales. Este espacio es referenciado por EBP quedando por arriba las variables y por abajo el saved EBP, return address y los argumentos. El ESP se moverá para poder dejar ese espacio a las variables hacia las direcciones más bajas de memoria. La función estará situada lógicamente en otra dirección de memoria, y queda referenciada cuando se llama. El stack crece hacia las direcciones más bajas de memoria.
Con esto me refiero a lo siguiente. Las tres primeras instrucciones de la función, configuran la pila o stack, y reciben el nombre de funciones de prologo o «Standard Entry Sequence» que varían según el compilador y sus opciones. Estamos hablando de:
A grandes rasgos, lo que hace estas tres instrucciones es:
- Colocar el puntero base en la pila o el Saved EBP.
- Mueve el contenido del puntero de pila al puntero base con el objetivo de colocar a este último en el Top del stack.
- Resta el valor en hexadecimal 0x18 al puntero base, con el fin dejar espacio en la pila disponible para las variables locales. Esto podéis verlo en la imagen del Stack, apreciando como el ESP esta por encima (o en las direcciones más bajas del stack) de las variables.
Ahora imaginaos «Imagine there’s no Heaven It’s easy if you try…(John Lennon)» un ejemplo, y es que dentro de la función main tenemos una función f. Un estilo a esto:
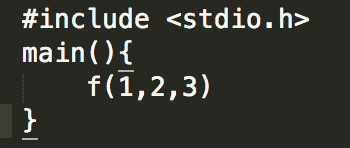
La instrucción CALL cambia el flujo del programa, llamando a otra función. Dentro de esta función tendrá sus correspondientes instrucciones y su instrucción de retorno. Antes de llamar a la función con call, si la función recibe argumentos se tiene que pasar a la pila esos argumentos, [ARG1,ARG2,ARG3]. Esto quiere decir que cuando se llama a la función, el EIP cambia y se usa la pila para recordar todas las variables locales.
Cuando realiza la llamada call, la dirección de retorno donde tiene que volver una vez finalice la función, debe ser guardada en el stack, la «return address» que corresponde con la siguiente dirección de memoria después de la llamada, y así usarse para devolver el EIP a la siguiente instrucción. Justo después de los argumentos. Tiene sentido ya que como veremos en el siguiente párrafo(Spoiler), en la pila se van apilando con push y se retira con pop, por tanto lo último que se retira del stack es la dirección de retorno de la función una vez finalice su flujo de ejecución. Como podéis ver en la imagen de abajo, con push se mandan los argumentos al stack antes de llamar a la función.
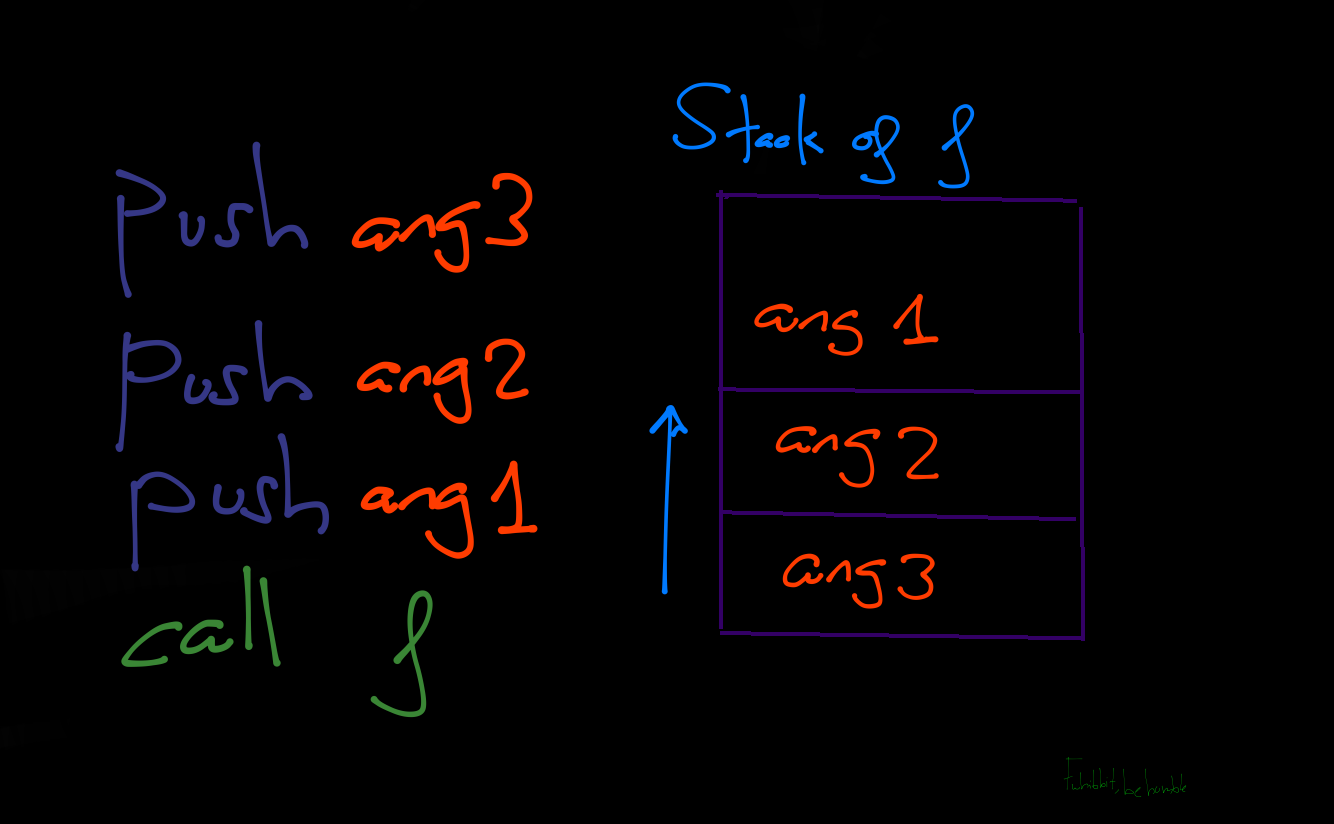
El siguiente paso es el Saved EBP, que lo vimos en el ejemplo real con la función de prologo.
Las instrucciones de acceso a la pila son PUSH y POP que básicamente es colocar en la pila y extraer de la pila respectivamente. La pila sigue el término FILO, «primero en entrar, último en salir», por tanto si realizamos la instrucción push para colocar los argumentos en la pila antes de llamar a la función, lo primero que habrá será esos argumentos antes de entrar en ella, y con pop el proceso inverso. El primer elemento que se ponga en la pila, es el último en salir.

Otro ejemplo más para que veamos el Stack de un código sencillo en C.
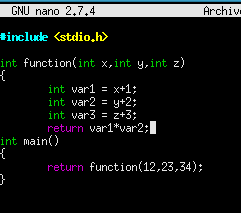
La pila tendría esta estructura.
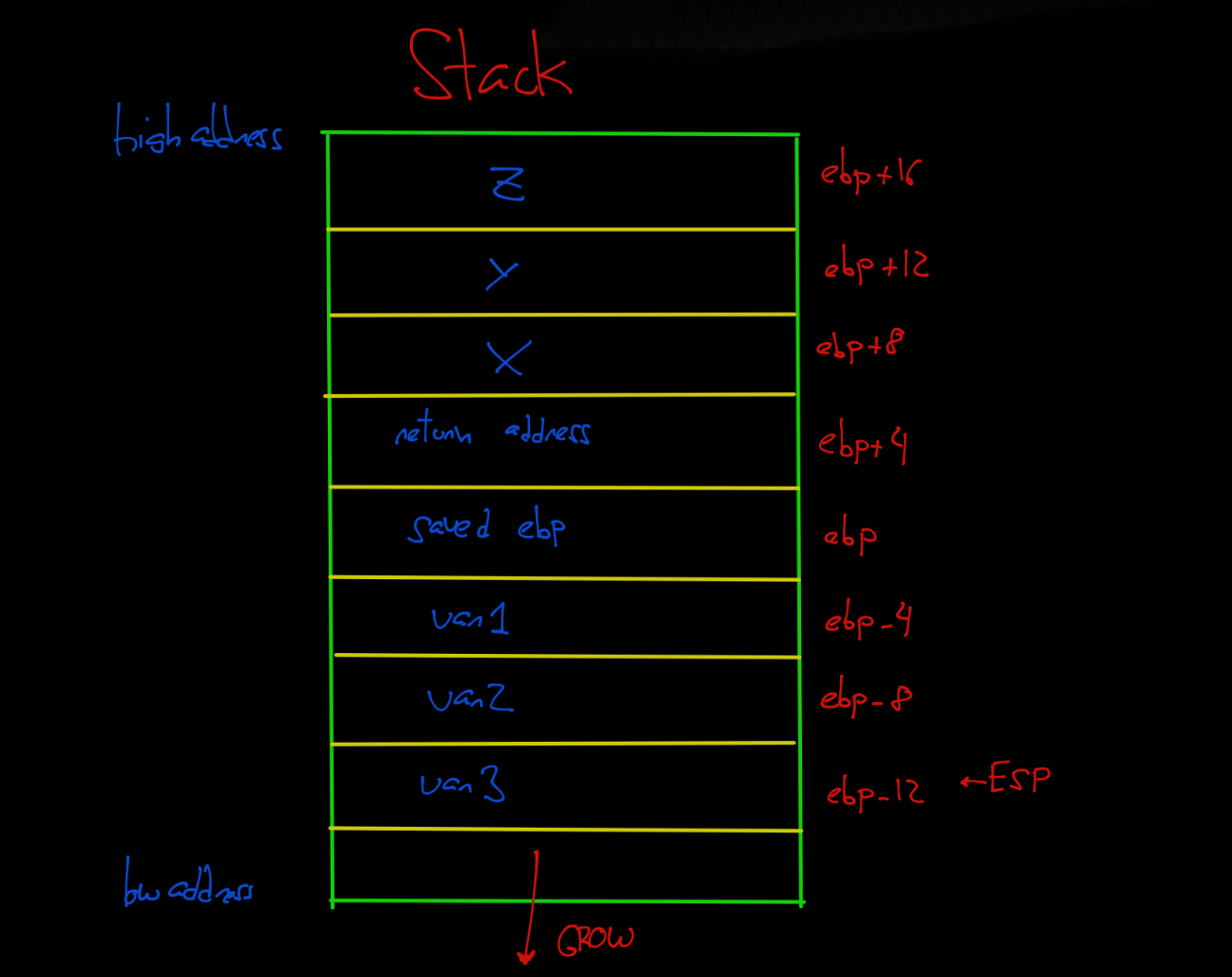
Ambos argumentos se pasan a la función, y las variables locales de esa función quedan almacenados en la pila cuando function() se llama. Este conjunto de datos en la pila se denomina marco para esta función.
ESP seguirá moviéndose a medida que la función se ejecuta, EBP (apuntador de base) se utiliza como un base de marco de pila al cual se pueden encontrar todos los argumentos de función y variables locales. Los argumentos están por encima de EBP en la pila (de ahí el desplazamiento positivo al acceder a ellos), mientras que las variables locales están por debajo de EBP en la pila.
Los beneficios del uso de la pila es que cuando termina la ejecución de la función, las variables locales creadas en esta se liberan automáticamente de la memoria. El ámbito de una variable local creada dentro de una función es la función en sí, por lo que cuando esta termina su ejecución, toda variable creada dentro de este ámbito es liberada automáticamente, a diferencia del segmento heap que hay que hacerlo manualmente.
El espacio reservado de memoria para el Stack crece y decrece conforme se ejecutan funciones, y terminan su ejecución. Como vimos anteriormente lo que queda almacenado en la pila y el correspondiente crecimiento hacia las direcciones más bajas de memoria, son las variables locales. Como es un segmento de tamaño variable, las instrucciones que hacen uso de ella para ese crecimiento y decrecimiento respectivamente eran push y pop.
Análisis estático del binario con radare2
Comencemos con algo muy sencillo, un código escrito en C interpretando su instrucciones en lenguaje ensamblador con la tool radare2.
 Analizamos con la opción «aaa» (strings,funciones,flags…)
Analizamos con la opción «aaa» (strings,funciones,flags…)
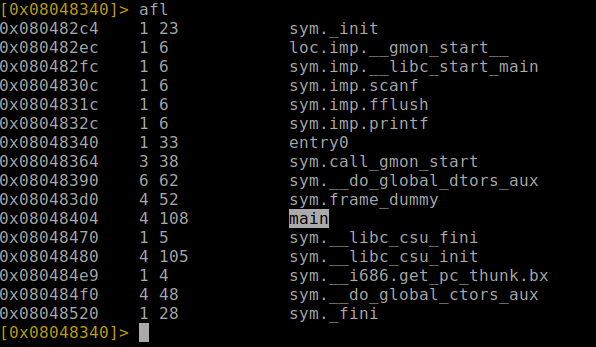
Con la opción «afl», buscamos todas las funciones disponibles en busca del main y con «s» buscamos la dirección virtual de la función en el binario. En este caso conocemos la función main, pero si tuviese el nombre correspondiente a la dirección de memoria, podemos hacer uso de !!rabin2 -z en busca de los strings en el binario con el prompt de r2. Si ejecutamos iz hace lo mismo, y con izz busca Strings en todo el binario no solo en .data.
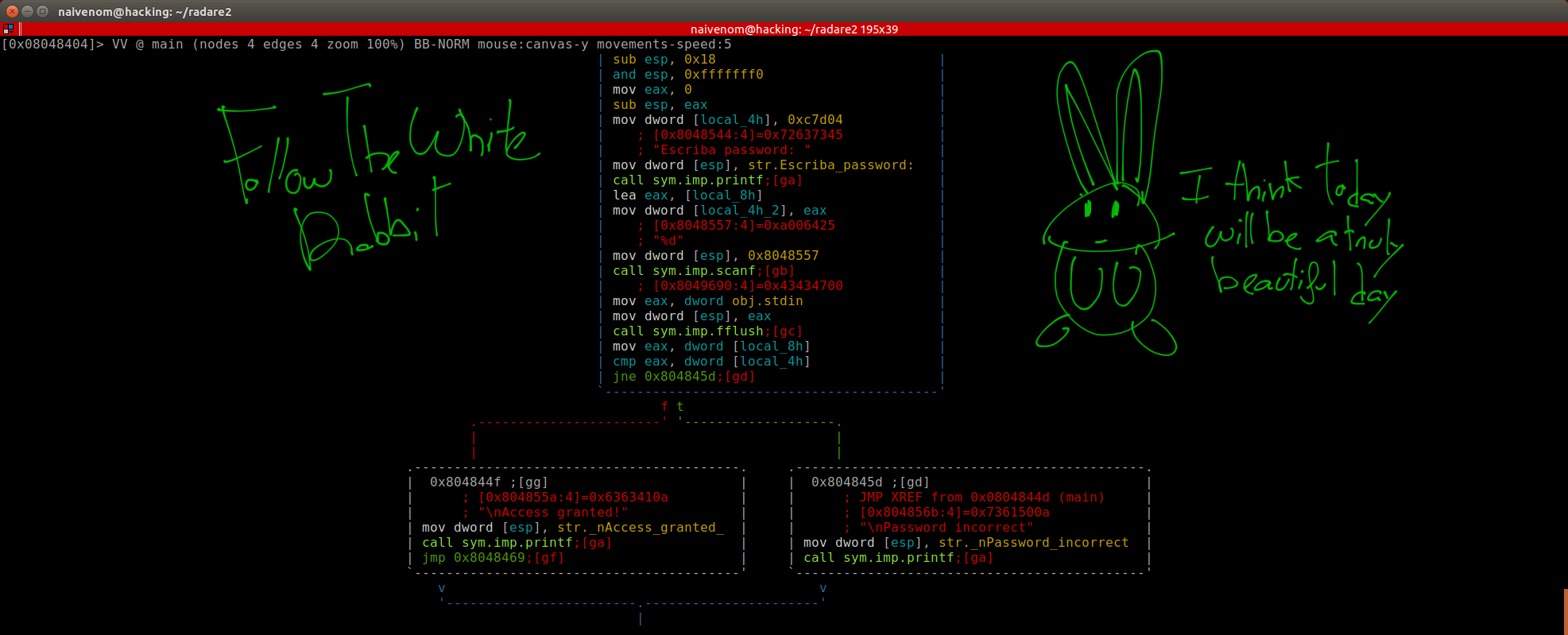
Con la opción «pdf», realizamos el desensamblado de la función main.
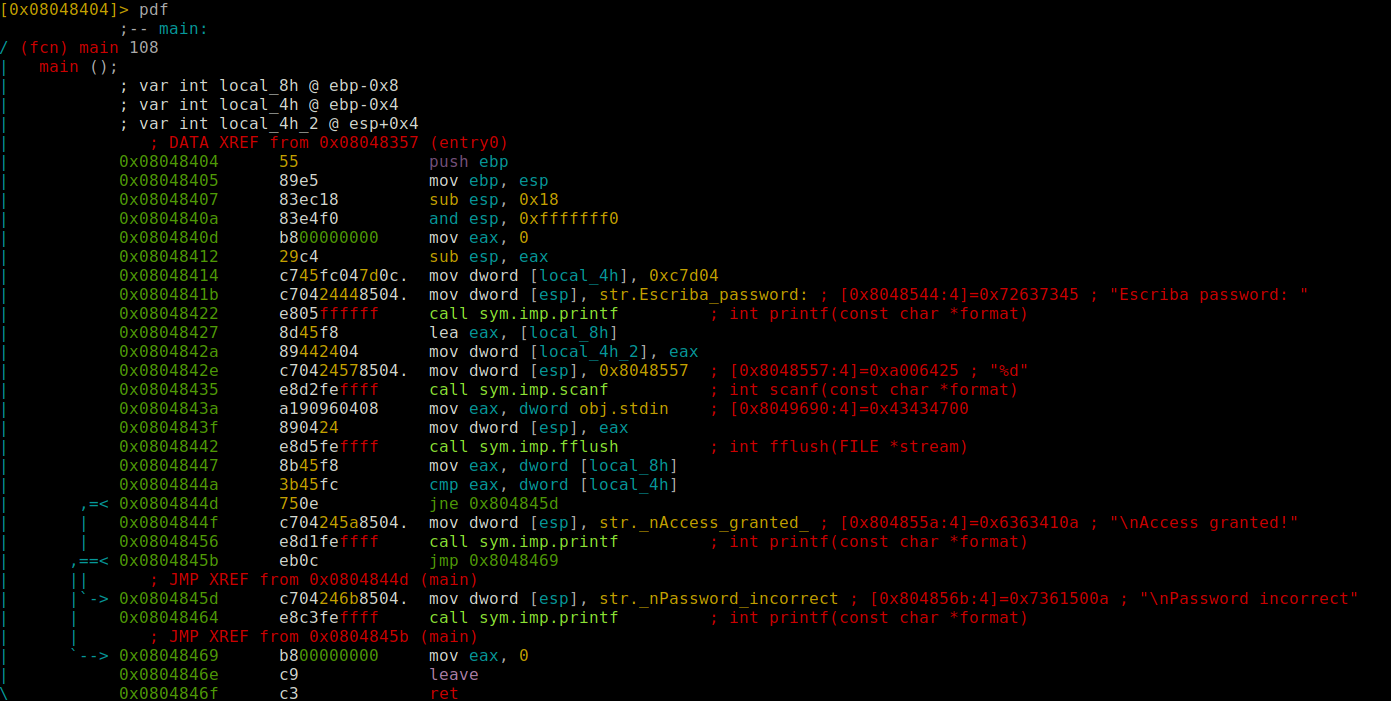
En un vistazo rápido podemos localizar tres variables, aunque en el código fuente solo hay dos, por tanto la otra la ha tenido que crear el compilador. También vemos instrucciones en ensamblador que veremos en detalle. Ahora volvemos a Matrix, y después de finalizar las instrucciones «Standard Entry Sequence» (vistas anteriormente en la entrada) desde la dirección de memoria 0x08048404 hasta 0x08048412, vemos otra instrucción MOV.
Nos permite mover contenido o direcciones de memoria del origen a destino, siguiendo esta estructura mov dest,orig. En este caso lo que hace es mover el contenido en hexadecimal a la memoria situada en la dirección almacenada en la variable local_4h o [ebp-4]. En ebp-4, es dónde esta almacenada la variable en la pila. Por lo tanto podemos deducir que es la inicialización de la variable en la función main.
![]()
El tamaño de los tipos de datos a grandes rasgos son:
- Byte: 8 bits, tipo char
- Word: 2 Bytes, tipo short
- Dword: 4 Bytes, tipo int
Por consiguiente, esta almacenando en la variable un valor de tipo int.
Las siguientes instrucciones realizan una acción muy parecida al anterior ejemplo que pusimos.
![]() Vemos como mueve mov la dirección de memoria 0x8048544 de la cadena «Escriba_password:» al final de su stack frame, a ESP. O dicho de otro modo, coloca en la pila un puntero (ESP) apuntando a la cadena de Strings, ya que esta cadena es el argumento de la función printf(). Así que esta función accede a sus parámetros a través del registro EBP.
Vemos como mueve mov la dirección de memoria 0x8048544 de la cadena «Escriba_password:» al final de su stack frame, a ESP. O dicho de otro modo, coloca en la pila un puntero (ESP) apuntando a la cadena de Strings, ya que esta cadena es el argumento de la función printf(). Así que esta función accede a sus parámetros a través del registro EBP.
Si printf() hubiera recibido más de un parámetro estos estarían de forma consecutiva desde EBP hacia las direcciones más altas de la pila. Y en el supuesto caso de recibir dos argumentos, accedería con [ebp+4], como vimos en la imagen superior del Stack.
 La siguiente llamada será a la función scanf() para poder leer la entrada estándar, es decir, lo que reciba por teclado. En nuestro caso será dígitos debido a que en la función elegimos «%d», por tanto lo formatea a tipo de datos integer. Esta función recibe dos argumentos, el primero es «%d» y el segundo la referencia a la variable declarada anteriormente para poder almacenar lo tecleado en esa variable ya formateado, es decir, &numero.
La siguiente llamada será a la función scanf() para poder leer la entrada estándar, es decir, lo que reciba por teclado. En nuestro caso será dígitos debido a que en la función elegimos «%d», por tanto lo formatea a tipo de datos integer. Esta función recibe dos argumentos, el primero es «%d» y el segundo la referencia a la variable declarada anteriormente para poder almacenar lo tecleado en esa variable ya formateado, es decir, &numero.
 Vemos una instrucción nueva LEA. Mueve la dirección de memoria a destino lea dest,origen. En este caso lo que hace es mover la dirección de memoria de la variable [local_8h] o [ebp-8] = ebp – 0x8 situada en la pila a eax. Esta variable corresponde con el valor que obtendrá la variable cuando se almacene leyendo de la entrada estándar. Por tanto, como es lógico de momento esa variable aun no contiene ningún valor, no esta inicializada. Ebp – 8, corresponde a donde esta situada la variable local en el stack con respecto a la base o marco de pila. Es menos 8 porque recordamos que la pila crece hacia las direcciones de memoria más bajas. Por tanto en nuestro dibujo básico que hicimos del stack, corresponde a local var2.
Vemos una instrucción nueva LEA. Mueve la dirección de memoria a destino lea dest,origen. En este caso lo que hace es mover la dirección de memoria de la variable [local_8h] o [ebp-8] = ebp – 0x8 situada en la pila a eax. Esta variable corresponde con el valor que obtendrá la variable cuando se almacene leyendo de la entrada estándar. Por tanto, como es lógico de momento esa variable aun no contiene ningún valor, no esta inicializada. Ebp – 8, corresponde a donde esta situada la variable local en el stack con respecto a la base o marco de pila. Es menos 8 porque recordamos que la pila crece hacia las direcciones de memoria más bajas. Por tanto en nuestro dibujo básico que hicimos del stack, corresponde a local var2.
En la siguiente instrucción se mueve con mov el contenido en el registro eax, en este caso, la dirección de memoria en la pila de la variable local_8h, al contenido [local_4h_2] o [esp+4] = esp+0x4, al puntero de pila +4. Es decir, esa variable corresponde al segundo argumento que recibe la función scanf(), y esa dirección apunta en la pila a la variable donde tiene que almacenar leyendo de la entrada estándar.
Y por último, antes de llamar a la función, mueve con mov la dirección de memoria donde se encuentra los strings correspondientes a «%d» que es el formateo de lectura de la entrada estándar a tipo de datos integer, al puntero de pila [esp]. Será el primer argumento que reciba la función al llamarse. La función scanf(), recibe como argumentos direcciones de memoria que se puede acceder a ellos gracias al puntero de pila del stack, y así escribir en la variable local_8h.
 Ahora mueve con mov, la dirección de memoria correspondiente al argumento que va a recibir la función fflush() al registro eax. El argumento que recibe es la dirección de memoria correspondiente a obj.stdin que es el buffer del teclado correspondiente a limpiar. Es recomendable su uso después de una función del tipo scanf(), ya que, antes de leer de la entrada estándar (stdin), esta vacío.
Ahora mueve con mov, la dirección de memoria correspondiente al argumento que va a recibir la función fflush() al registro eax. El argumento que recibe es la dirección de memoria correspondiente a obj.stdin que es el buffer del teclado correspondiente a limpiar. Es recomendable su uso después de una función del tipo scanf(), ya que, antes de leer de la entrada estándar (stdin), esta vacío.
Antes de llamar a la función, mueve lo contenido en el registro eax, al puntero de pila [esp], es decir, coloca un puntero apuntando a la dirección de memoria siendo el argumento que recibirá la función fflush(). <stdio.h> esta incluida en el código C que programamos para hacer este sencillo ejemplo. Contiene referencias para poder usarlas en las funciones como printf() stdout, salida estándar por pantalla o scanf() stdin, salida estándar por teclado.
 En la siguiente instrucción mueve mov el contenido de la variable local_8h al registro eax. CMP, compara el valor o contenido de la variable local_4h con el registro eax que en este momento es igual a la variable local_8h. Si son iguales activará una flag que dependiendo de la siguiente instrucción que es un salto condicional, hará una cosa u otra. Las eflags lo veremos más en detalle con el Debugger en la siguiente entrada, pero son básicamente marcadores de bits(0 o 1) para realizar comparaciones antes de realizar un salto condicional.
En la siguiente instrucción mueve mov el contenido de la variable local_8h al registro eax. CMP, compara el valor o contenido de la variable local_4h con el registro eax que en este momento es igual a la variable local_8h. Si son iguales activará una flag que dependiendo de la siguiente instrucción que es un salto condicional, hará una cosa u otra. Las eflags lo veremos más en detalle con el Debugger en la siguiente entrada, pero son básicamente marcadores de bits(0 o 1) para realizar comparaciones antes de realizar un salto condicional.
cmp resta el origen al destino, sin almacenar el contenido en destino. Altera el estado de la flag. Entonces en un salto condicional usa el resultado de la comparación, quedándose almacenado en las eflags, haciendo que el eip apunte a una u otra dirección de memoria dependiendo del tipo de salto.
JNE es un salto condicional en el que salta si no es igual o salta si no es cero. El salto se efectuá, es decir, si es True(Linea Verde) ZF(Zero Flag)=0. Es justo lo contrario a JE, que salta si es igual o cero y en este caso la ZF=1.
Para poder verlo en modo gráfico usamos «Vpp» y seguidamente «Espacio».
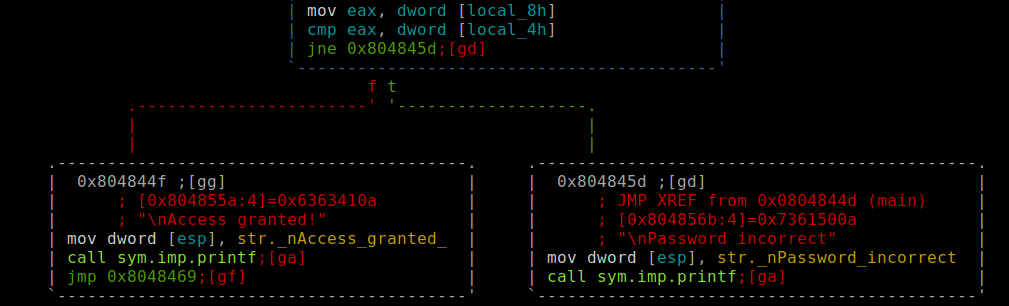 Por tanto como ZF su bit es = 0, y según este salto condicional jne solo salta si no es igual o no es cero, cumple la condición solo cuando la comparación cmp entre ambos son distintos o no son cero .
Por tanto como ZF su bit es = 0, y según este salto condicional jne solo salta si no es igual o no es cero, cumple la condición solo cuando la comparación cmp entre ambos son distintos o no son cero .
El contenido de local_4h, es la password que tenemos que «saber» para poder acertar, comparándolo con lo introducido mediante la función scanf() almacenada en la variable local_8h.
En el caso de que la ZF=1, quiere decir que en la comparación son iguales, por tanto, hemos acertado el numero. Para poder ver el estado de las eflags, podemos hacerlo con el Debugger que nos ofrece la tool radare2, y así ver también el EIP y demás registros, pero lo veremos en la siguiente entrada.
Un saludo, Naivenom
6 comentarios en «Introducción al Reversing con radare2 – 0x00 Introduccion»
Buen articulo de ingenieria inversa, sigo atento para las continuaciones. Quusiera preguntar sobre el desbordamiento de buffer para el analisis de algunos malwares y ransoweres.
Gracias por compartir !!
Gracias saludos
Excelente articulo, desde hoy he empezado a seguir tus articulos, en verdad me siento maravillado con tal excelente explicacion punto a punto, creeme que es de los mejores contenidos que he encontrado, te mando un saludo y abrazo gigante desde Colombia ( te confieso que la ingenieria inversa la llevo conociendo hace varios años atrás pero siempre habia caido en el no entendimiento y me rendía, ya estoy volviendo a retomar ) me siento orgulloso de encontrar esta informacion y mejor aun, en español, te felicito en verdad, espero algun dia poder conocerte y charlar un rato!
Los comentarios están cerrados.