
Hola a todos!
En esta entrada me gustaría continuar el tema de scraping web para orientarlo a OSINT, no empezaré por lo básico (qué es scraping etc…), pues mi compañero Alejandro ya habló del tema en el siguiente artículo:
Bien! Si has llegado hasta aquí entiendo que ya sabes lo que significa la palabra scraping, si no es así, pulsa en el artículo de arriba 😉
Con la creación de esta entrada pretendo generar curiosidad, que comprobéis lo fácil e importante que puede ser scrapear internet para una persona y/o empresa. Pero no seáis malos 😛
Para esta entrada necesitamos instalar searx (pronto veréis para que), pero…
¿Qué es Searx?
Searx es un motor gratuito de búsqueda en Internet. Searx agrega los resultados de más de 70 servicios de búsqueda. Como punto fuerte, searx destaca en que los usuarios no son ni rastreados ni perfilados. Además se puede utilizar sobre Tor para el anonimato en línea.
Características
- Lo hospedas en tu propio servidor.
- No hay seguimiento de usuarios.
- No hay perfiles de usuario.
- 70 motores de búsqueda soportados.
- Fácil integración con cualquier motor de búsqueda.
- No se utilizan cookies de forma predeterminada.
- Conexiones seguras y cifradas (HTTPS / SSL).
- Organizado por organizaciones que promueven los derechos digitales.
Si tenéis más curiosidad sobre Searx podéis leer más sobre el tema en su página oficial
Lo primero que tenemos que hacer es descargar searx de su repositorio oficial en github:
git clone https://github.com/asciimoo/searx.git
Acto seguido, accederemos al directorio descargado y ejecutaremos manage.sh con el parámetro «update_packages» para actualizar e instalar todas las librerias dependientes.
./manage.sh update_packages
![]()
Una vez haya finalizado la instalación, recomiendo generar una clave aleatoria, para ello deberemos ejecutar:
sed -i -e "s/ultrasecretkey/`openssl rand -hex 16`/g" searx/settings.yml
![]()
El siguiente paso es introducir nuestra IP en el fichero de configuración (searx/settings.yml). y el puerto que queremos utilizar:

Por último, queda ejecutar searx:
python searx/webapp.py
Accedemos vía navegador y…

Bien, llegados a este punto podréis comprobar que el buscador funciona perfectamente:
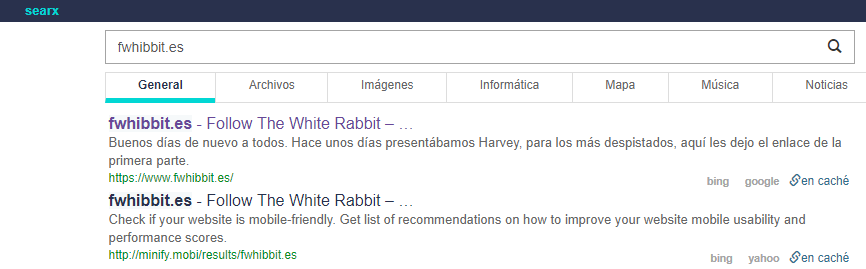
Si Searx funciona correctamente, es recomendable desactivar el modo debug, para ello basta con ejecutar:
sed -i -e "s/debug : True/debug : False/g" searx/settings.yml
Estoy seguro de que todos conocemos Pastebin, sin duda sería un gran lugar para scrapear, pues cuenta con muchísima información útil (y otra mucha no tanto).
Y como todo no podía ser bonito, nos toca pagar una cuenta premium en pastebin, para evitar baneos de IP al scrapear, pero tranquilos, es bastante asequible y esto es opcional, podéis continuar scrapeando el resto de páginas web (más adelante lo comprobaréis :P).
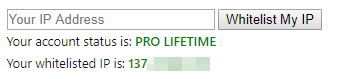
En mi caso si quería acceder a Pastebin, así que compré la cuenta premium (no me matéis por esto xD):
Y añadí mi IP a la lista blanca: https://pastebin.com/api_scraping_faq
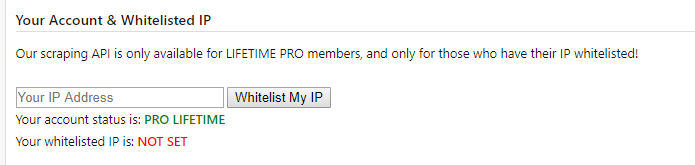
Hace un tiempo encontré un script bastante bueno que permitía automatizar el web scraping a través de Searx (ahora lo entendéis todo ¿verdad?), el script en cuestión es el siguiente:
https://github.com/automatingosint/osint_public/blob/master/keyword_monitor/keywordmonitor.py
Para trabajar con él bastará con hacer un git clone 🙂
Una vez tengamos nuestro script, debemos crear un fichero llamado keywords.txt con las palabras o palabras (pueden ser frases) que queremos monitorizar.

En mi caso puse algo bastante común.
![]()
Ahora editamos el script y modificamos los datos de envío. El script envía cada ciertas «repeticiones» un correo con las URLs encontradas, bastará con introducir por ejemplo un gmail o configurar la cuenta (y el servidor SMTP) que queramos.
Importante también, configurar correctamente el campo searx_url con la dirección de nuestro searx.
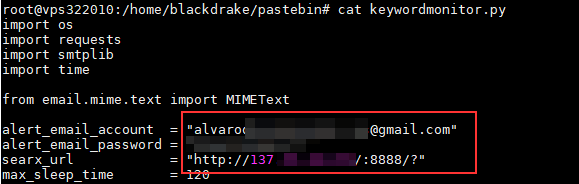
En caso de que utilicéis gmail es importante que habilitéis el acceso a aplicaciones no seguras, para ello debemos acceder a los siguientes enlaces: https://myaccount.google.com/security y https://accounts.google.com/DisplayUnlockCaptcha
Nota: Recomiendo que os creéis una cuenta para esto.
Bastará con acceder a Seguridad y activarlo:
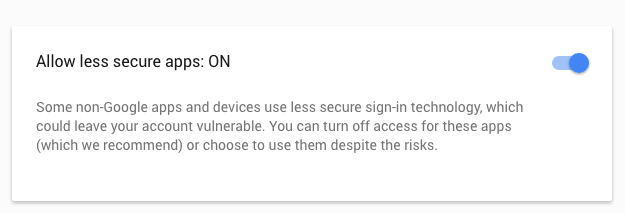
Con el segundo enlace, bastará con darle a Continuar.
Para finalizar, ejecutamos el script para que comience a monitorizar.
IMPORTANTE! Si no queréis utilizar Pastebin, comentar las funciones para evitar que el script monitorice dicha página.
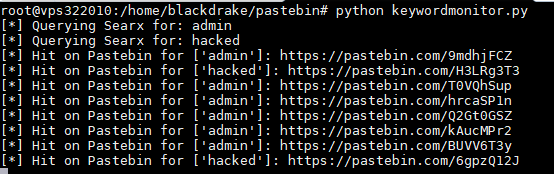
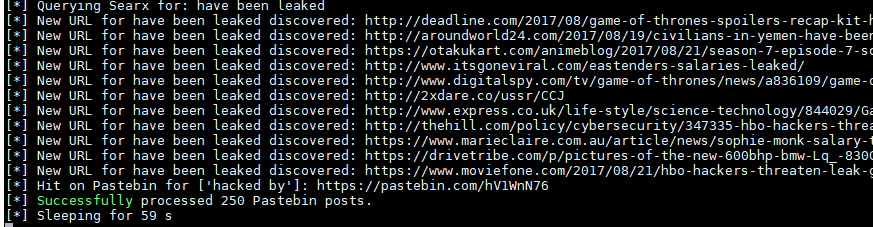
Como véis, no solo busca en Pastebin:
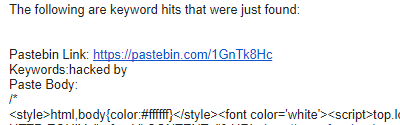
Y aquí uno de los correos que recibimos:
Personalmente he modificado el código añadiéndole ciertas mejoras (bajo mi punto de vista), por ejemplo ya no envía correos, el principal motivo era que enviaba el body haciendo eterno el correo, además, teniendo los enlaces vía email era bastante complejo tratarlos, así que ahora guardo toda la información en una base de datos.
Espero que os haya gustado esta entrada y que cada uno lo adapte a sus necesidades.
Un saludo,
Álvaro Díaz (@alvarodh5)
Un comentario en «OSINT: Web Scraping»
Excelente post sobre web scraping.
Aprovrcho la ocasión para hacer una pregunta sobre web scraping, utilizo scrapy con Python. Estoy extrayendo datos de diferentes paginas web, y algunas me han baneado despues de varias veces de haber lanzado la araña a su web. Estoy buscando la manera de aprender a evitar este tipo de problemas ¿Podria decirme como hacer, o donde puedo investigar? Al leer el post y ver lo de la ip en pastebin y demas me ha parecido que hay solución a mi problema.
Gracias por anticipado por su respuesta
Los comentarios están cerrados.