Colaborador: Vasco
Buenos días a tod@s, continuando la serie de entradas sobre scripts en Python, en la primera vimos Crypt-Decrypt con el que podemos cifrar palabras e identificar o descifrar hashes en varios algoritmos, en esta ocasión le toca el turno a Shodan. Para el que no lo conozca, algo raro…, se trata de un buscador igual que Google o Bing con la diferencia que no busca webs o documentos sino equipos conectados a internet como pueden ser servidores, impresoras, webcams, routers, etc.
Mediante el script de hoy, Shodan_cmd, vamos a poder hacer búsquedas en Shodan, obtener información sobre un host o rango de hosts, buscar exploits, guardar los resultados en un archivo, guardar solo los campos elegidos de cada resultado, etc. A continuación la pantalla de ayuda y ejemplos de uso.
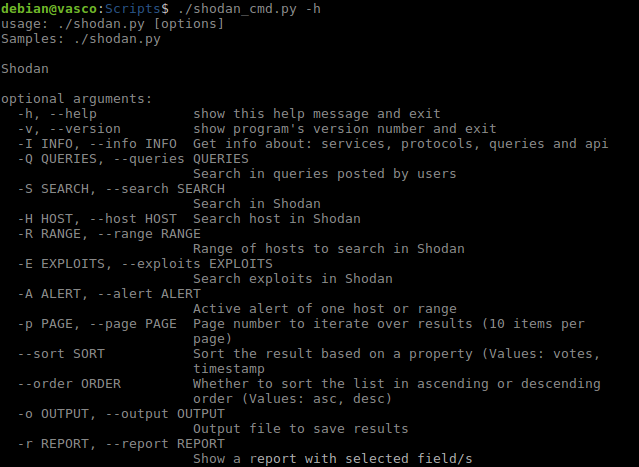 Comando Ayuda.
Comando Ayuda.
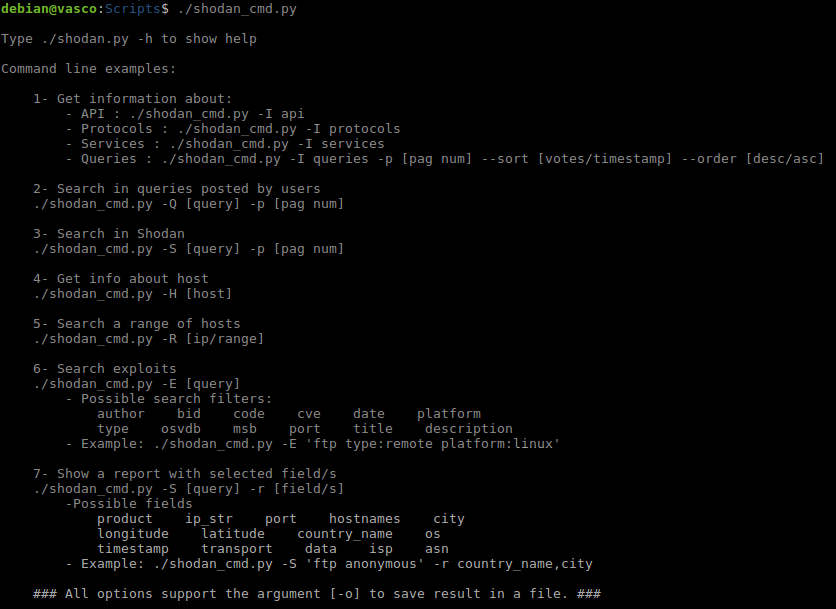 Ejemplos de uso.
Ejemplos de uso.
En esta ocasión he creado una clase principal que contiene todas las funciones necesarias (llamadas métodos) para las distintas opciones. Inicializamos la clase con el método __init__ pasándole como atributo nuestra API de Shodan.
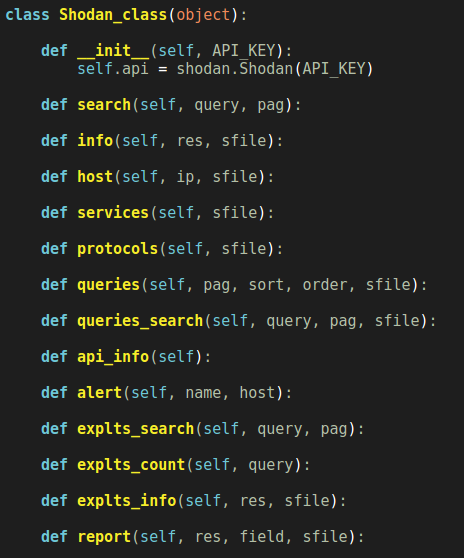
Empecemos con las distintas opciones disponibles, en primer lugar -I Information, mediante la cual vamos a obtener info sobre:
Protocolos: muestra una lista de protocolos compatibles con la API de búsqueda de Shodan.
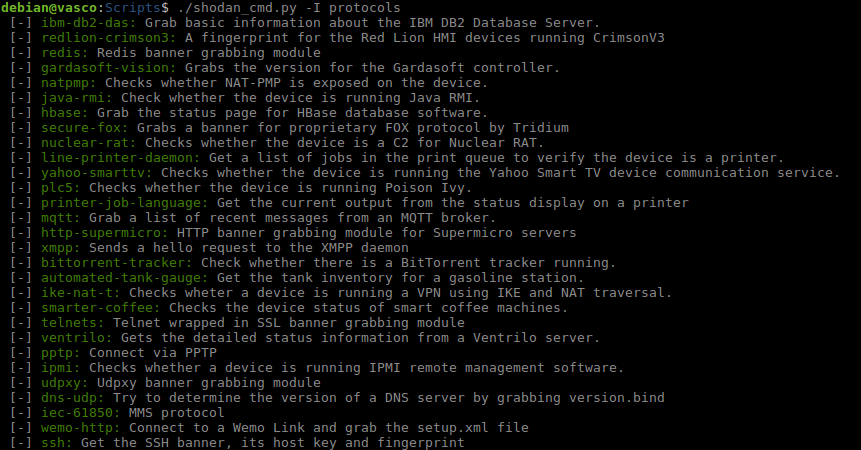 Lista de protocolos.
Lista de protocolos.
def protocols(self, sfile): result = self.api.protocols() if sfile is None: for x, y in result.items(): print(" [-] " + colors.GREEN + x + ": " + colors.ENDC + y) else: with open(sfile, 'w') as f: for x, y in result.items(): f.write("\n [-] %s: %s" % (x, y)) print(" [i] " + colors.GREEN + "File saved!!\n" + colors.ENDC)
Todos los métodos de una clase reciben como primer parámetro self con el que se le pasa el objeto. El segundo parámetro es sfile que se trata de la ruta del archivo donde queremos guardar el resultado (en caso de que sea así).
- Linea 1: declaramos la variable result y le asignamos como valor el resultado de la consulta hecha con la API, que en este caso nos devuelve un diccionario.
- Linea 2: en caso de que sfile sea None (no se ha indicado un archivo para guardar).
- Linea 3 – 4: recorremos los items del diccionario y se muestran por pantalla.
- Linea 5: en el caso contrario que sfile no sea None.
- Linea 6: abrimos el archivo en modo escritura con ‘w’.
- Linea 7 – 8: recorremos el diccionario igual que antes pero guardándolos en el archivo.
Servicios: nos devuelve un diccionario con la lista de servicios, y su correspondiente puerto, rastreados por Shodan.
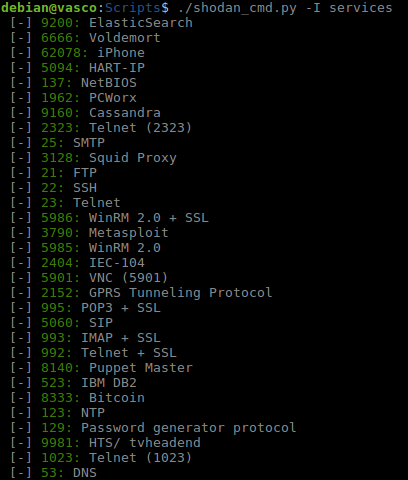 Lista de servicios.
Lista de servicios.
def services(self, sfile): result = self.api.services() if sfile is None: for x, y in result.items(): print(" [-] " + colors.GREEN + x + ": " + colors.ENDC + y) else: with open(sfile, 'w') as f: for x, y in result.items(): f.write("\n [-] %s: %s" % (x, y)) print(" [i] " + colors.GREEN + "File saved!!\n" + colors.ENDC)
Al igual que con los protocolos, realizamos la consulta con la API y comprobamos si se ha indicado un archivo para guardar el resultado o en caso contrario mostrarlo por pantalla.
API: obtendremos información sobre la API que estemos utilizando como los créditos disponibles, si tenemos activado Telnet y HTTPS, etc.
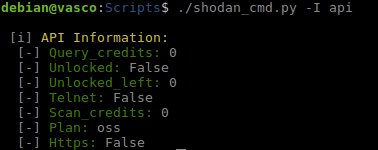 Información API.
Información API.
def api_info(self): result = self.api.info() print("\n [i] " + colors.INFO + "API Information:" + colors.ENDC) for x, y in result.items(): print(" [-] " + colors.GREEN + str(x).capitalize() + ": " + colors.ENDC + str(y))
En esta función simplemente realizamos la consulta y recorremos el diccionario devuelto para mostrar por pantalla los pares de clave y valor. En la clave usamos capitaliza() para poner la primera letra en mayúsculas.
Queries: obtenemos una lista con las consultas compartidas por otros usuarios. Podemos indicar números de página, ordenar por votos recibidos o fecha y con orden ascendente o descendente.
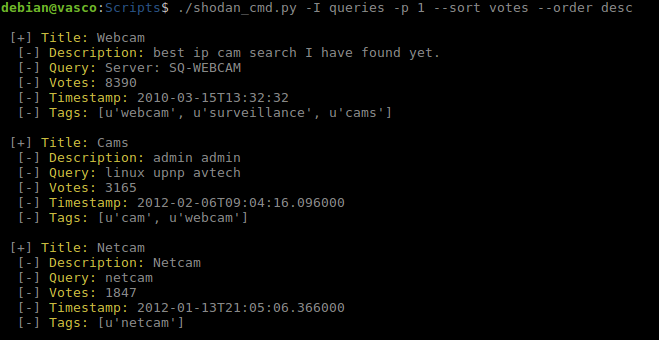 Lista de queries publicadas.
Lista de queries publicadas.
def queries(self, pag, sort, order, sfile): res = self.api.queries(page=pag, sort=sort, order=order) if sfile is None: i = 0 for r in res['matches']: print("\n [+]" + colors.INFO + " Title: " + colors.ENDC + r.get('title', 'Unknown')) print(" [-]" + colors.INFO + " Description: " + colors.ENDC + r.get('description', 'Unknown')) print(" [-]" + colors.INFO + " Query: " + colors.ENDC + r.get('query', 'Unknown')) print(" [-]" + colors.INFO + " Votes: " + colors.ENDC + str(r.get('votes'))) print(" [-]" + colors.INFO + " Timestamp: " + colors.ENDC + r.get('timestamp')) print(" [-]" + colors.INFO + " Tags: " + colors.ENDC + str(r.get('tags', 'Unknown'))) i += 1 if i == 3: raw_input("\npress enter to continue...") i = 0 else: with open(sfile, "a+") as f: for r in res['matches']: f.write("\n\n [+] Title: " + r.get('title', 'Unknown')) f.write("\n [-] Description: " + r.get('description', 'Unknown')) f.write("\n [-] Query: " + r.get('query', 'Unknown')) f.write("\n [-] Votes: " + str(r.get('votes'))) f.write("\n [-] Timestamp: " + r.get('timestamp')) f.write("\n [-] Tags: " + str(r.get('tags', 'Unknown'))) print(" [i] " + colors.GREEN + "File saved!!\n" + colors.ENDC)
En este caso la función es un poco diferente, le pasamos 3 parámetros nuevos, además de los antes vistos, que son pag (número de paginas), sort (campo por el que ordenar los resultados: vote o timestamp) y order (orden ascendente o descendente). Analizemos el código.
- Linea 1: hacemos la consulta pasándole los parámetros. Nos devuelve un diccionario que a su vez contiene varios diccionarios, uno por cada resultado encontrado.
- Linea 2: en caso de que no se haya indicado un archivo…
- Linea 3: se declara la variable i con valor 0.
- Linea 4: un bucle que recorre cada diccionario contenido en el diccionario matches.
- Linea 5 – 10: obtenemos cada elemento del diccionario con su clave mediante .get, de esta forma si no existiera la clave nos devuelve el valor por omisión establecido Unknown, o en su defecto None.
- Linea 11 – 14: sumamos 1 a la variable i por cada resultado mostrado, si i vale 3, esperamos una pulsación de la tecla enter, de esta forma muestra los resultados de 3 en 3, por último establecemos nuevamente la variable i con valor 0.
- Linea 15 y siguientes: en caso de que se haya indicado un archivo, hacemos exactamente lo mismo de antes pero esta vez escribiendo los resultados en el archivo indicado. Abrimos el archivo con «a+» por dos motivos, el primero para que no sobrescriba el contenido del archivo sino que escriba a continuación y segundo para que cree el archivo en caso de no existir.
El problema es que mediante queries, aunque podemos indicar algunos filtros como el orden, no nos permite indicar una palabra clave a buscar, para ello tenemos la siguiente opción.
Queries_search (-Q): como he comentado antes, nos permite indicar una palabra clave para buscar las queries relacionadas con la misma.
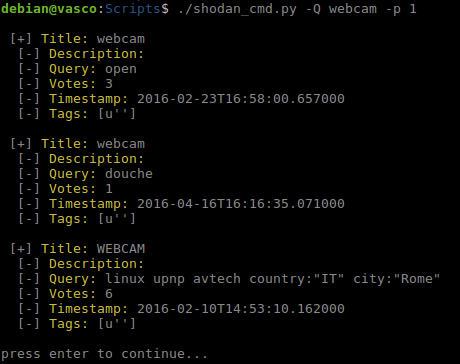 Opción Queries_search.
Opción Queries_search.
def queries_search(self, query, pag, sfile): res = self.api.queries_search(query, pag) if sfile is None: i = 0 for r in res['matches']: print("\n [+]" + colors.INFO + " Title: " + colors.ENDC + r.get('title', 'Unknown')) print(" [-]" + colors.INFO + " Description: " + colors.ENDC + r.get('description', 'Unknown')) print(" [-]" + colors.INFO + " Query: " + colors.ENDC + r.get('query', 'Unknown')) print(" [-]" + colors.INFO + " Votes: " + colors.ENDC + str(r.get('votes'))) print(" [-]" + colors.INFO + " Timestamp: " + colors.ENDC + r.get('timestamp')) print(" [-]" + colors.INFO + " Tags: " + colors.ENDC + str(r.get('tags', 'Unknown'))) i += 1 if i == 3: raw_input("\npress enter to continue...") i = 0 else: with open(sfile, "a+") as f: for r in res['matches']: f.write("\n\n [+] Title: " + r.get('title', 'Unknown')) f.write("\n [-] Description: " + r.get('description', 'Unknown')) f.write("\n [-] Query: " + r.get('query', 'Unknown')) f.write("\n [-] Votes: " + str(r.get('votes'))) f.write("\n [-] Timestamp: " + r.get('timestamp')) f.write("\n [-] Tags: " + str(r.get('tags', 'Unknown'))) print(" [i] " + colors.GREEN + "File saved!!\n" + colors.ENDC)
La única diferencia con la antes vista está en los parámetros que le pasamos, query (palabra clave), y ya no es necesario pasarle sort y order, por lo demás es el mismo mecanismo, hacemos la consulta con la API y comprobamos si se ha indicado un archivo para guardar el resultado o por el contrario mostrarlo por pantalla.
Es el turno de Search (-S) que nos va permitir realizar una búsqueda típica en Shodan, al igual que lo haríamos desde la web. Consta de dos funciones, search que realiza la consulta con la API y devuelve el resultado, luego esta la función info que se encarga de procesar el resultado devuelto por search para mostrarlo por pantalla o guardarlo en un archivo según se indique.
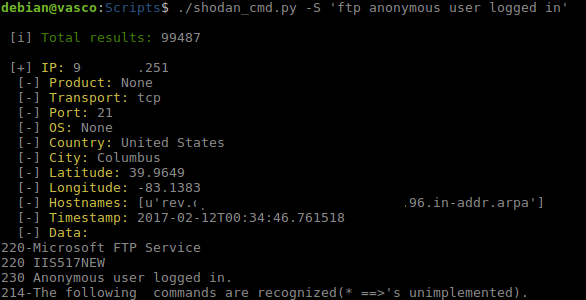 Comando Search.
Comando Search.
def search(self, query, pag): try: result = self.api.search(str(query), pag) except Exception as e: print(colors.FAIL + "\n [!] ERROR: " + colors.ENDC + str(e)) result = [] return result
Le pasamos dos parámetros, query qeu equivale al texto que escribimos en la web para buscar y pag que es el número de páginas a mostrar (si la API que estamos usando es de una cuenta gratuita, no nos permitirá mostrar mas de una página).
- Linea 1: con try controlamos los errores que puedan darse.
- Linea 2: hacemos la consulta y asignamos la salida a la variable result.
- Linea 3 – 5: en caso de error, mostramos un mensaje con el mismo y dejamos vacía la variable result.
- Linea 6: devolvemos result.
def info(self, res, sfile): if sfile is None: i = 0 for r in res['matches']: print("\n [+]" + colors.INFO + " IP: " + colors.ENDC + r.get('ip_str')) print(" [-]" + colors.INFO + " Product: " + colors.ENDC + str(r.get('product'))) print(" [-]" + colors.INFO + " Transport: " + colors.ENDC + str(r.get('transport'))) print(" [-]" + colors.INFO + " Port: " + colors.ENDC + str(r.get('port'))) print(" [-]" + colors.INFO + " OS: " + colors.ENDC + str(r.get('os'))) print(" [-]" + colors.INFO + " Country: " + colors.ENDC + str(r['location']['country_name'])) print(" [-]" + colors.INFO + " City: " + colors.ENDC + str(r['location']['city'])) print(" [-]" + colors.INFO + " Latitude: " + colors.ENDC + str(r['location']['latitude'])) print(" [-]" + colors.INFO + " Longitude: " + colors.ENDC + str(r['location']['longitude'])) print(" [-]" + colors.INFO + " Hostnames: " + colors.ENDC + str(r.get('hostnames'))) print(" [-]" + colors.INFO + " Timestamp: " + colors.ENDC + str(r.get('timestamp'))) print(" [-]" + colors.INFO + " Data: \n" + colors.ENDC + str(r['data'])) i += 1 if i == 2: raw_input("\npress enter to continue...") i = 0 else: with open(sfile, "a+") as f: for r in res['matches']: f.write("\n\n [+] IP: " + r.get('ip_str')) f.write("\n [-] Product: " + str(r.get('product'))) f.write("\n [-] Transport: " + str(r.get('transport'))) f.write("\n [-] Port: " + str(r.get('port'))) f.write("\n [-] OS: " + str(r.get('os'))) f.write("\n [-] Country: " + str(r['location']['country_name'])) f.write("\n [-] City: " + str(r['location']['city'])) f.write("\n [-] Latitude: " + str(r['location']['latitude'])) f.write("\n [-] Longitude: " + str(r['location']['longitude'])) f.write("\n [-] Hostnames: " + str(r.get('hostnames'))) f.write("\n [-] Timestamp: " + str(r.get('timestamp'))) f.write("\n [-] Data: \n" + str(r['data'])) print(" [i] " + colors.GREEN + "File saved!!\n" + colors.ENDC)
Esta función es la encargada de mostrar o guardar el resultado obtenido con search. Es el mismo sistema qeu se ha visto con las queries, usamos un bucle for para recorrer los diccionarios contenidos en matches y los mostramos o guardamos dependiendo de si se ha indicado un archivo o no.
En Shodan también podemos buscar una ip en concreto para obtener información como puertos abiertos y sus banners, geolocalizacion, ciudad, país, etc. Esto mismo es posible realizarlo con el script mediante la opción -H de host.
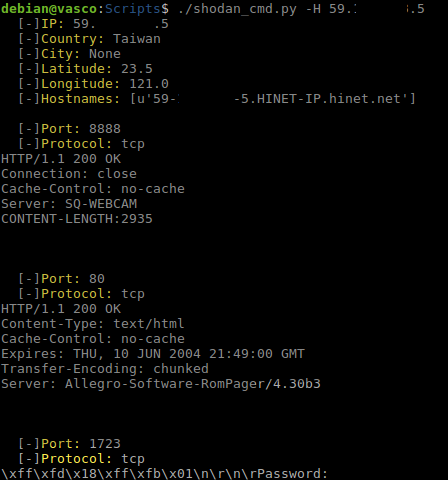 Información de un host.
Información de un host.
def host(self, ip, sfile): try: host = self.api.host(ip) if sfile is None: print("\n [+]" + colors.INFO + "IP: " + colors.ENDC + host.get('ip_str')) print(" [-]" + colors.INFO + "Country: " + colors.ENDC + host.get('country_name', 'Unknown')) print(" [-]" + colors.INFO + "City: " + colors.ENDC + str(host.get('city', 'Unknown'))) print(" [-]" + colors.INFO + "Latitude: " + colors.ENDC + str(host.get('latitude'))) print(" [-]" + colors.INFO + "Longitude: " + colors.ENDC + str(host.get('longitude'))) print(" [-]" + colors.INFO + "Hostnames: " + colors.ENDC + str(host.get('hostnames'))) for x in host['data']: print("\n [-]" + colors.INFO + "Port: " + colors.ENDC + str(x['port'])) print(" [-]" + colors.INFO + "Protocol: " + colors.ENDC + x['transport']) print(x['data']) else: with open(sfile, 'a+') as f: f.write("\n\n [+] IP: " + host.get('ip_str')) f.write("\n [-] Country: " + host.get('country_name', 'Unknown')) f.write("\n [-] City: " + str(host.get('city', 'Unknown'))) f.write("\n [-] Latitude: " + str(host.get('latitude'))) f.write("\n [-] Longitude: " + str(host.get('longitude'))) f.write("\n [-] Hostnames: " + str(host.get('hostnames'))) for x in host['data']: f.write("\n [-] Port: " + str(x['port'])) f.write("\n [-] Protocol: " + x['transport'] + "\n") f.write(x['data']) print(" [i] " + colors.GREEN + "File saved!!\n" + colors.ENDC) except Exception as e: print(colors.FAIL + colors.BOLD + "\n [!] ERROR: " + colors.ENDC + str(e) + "\n")
Es igual que las antes vistas, consulta con la API, comprobar si se ha indicado un archivo y actuar en consecuencia mostrando o guardando la salida.
Es posible buscar un rango de ips mediante el filtro net:192.168.1.0/24, lo que pasa que escanea toda la red. Pero ¿y que pasa si no queremos escanear toda la red y solo un rango mas concreto?, si introducimos net:192.168.1.100/150 no muestra resultados, por ello he añadido otra opción al script para buscar un rango de ips mas específico, lo que hace básicamente es realizar una consulta por cada ip en el rango.
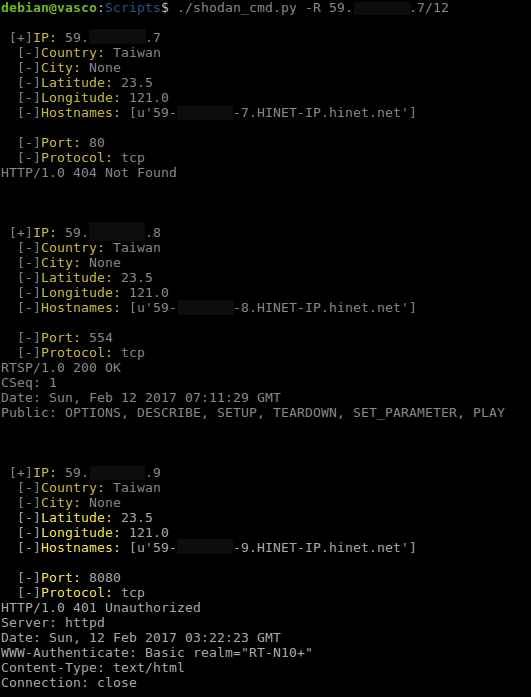 Rango de ips.
Rango de ips.
El código para esta opción es muy simple puesto que se utiliza la función host antes vista en un bucle que la ejecuta una vez por cada ip en el rango indicado.
rng = args.range ip = rng.split('/')[0] base = ip.split('.')[:3] range1 = int(ip.split('.')[3]) range2 = int(rng.split('/')[1]) for i in range(range1, range2): host = '.'.join(base) + '.' + str(i) shd.host(host, args.output) time.sleep(1)
- Linea 1: asignamos a la variable rng el valor del argumento range (ip/rango).
- Linea 2: dividimos con .split el valor de rng para obtener solo la ip.
- Linea 3: separamos la ip por los puntos con .split y guardamos en la variable solo los 3 primeros octetos.
- Linea 4: guardamos en range1 el último octeto de la ip que va ser el primer número del rango a buscar.
- Linea 5: obtenemos el último número del rango.
- Linea 6: bucle for que recorre los números comprendidos entre los dos obtenidos anteriormente.
- Linea 7: formamos la ip juntando los 3 primeros octetos y el número del rango.
- Linea 8: se realiza la consulta mediante la función host.
- Linea 9: con time.sleep hacemos que espere 1 segundo entre consulta y consulta (he tenido algunos fallos en caso de no ponerlo).
Además de servidores, impresoras o cualquier otro dispositivo conectado a internet, en Shodan es posible buscar exploits, algo que también podemos hacer con la API. Para ello he creado dos funciones, una para hacer la búsqueda (explts_search) y otra para manipular el resultado (explts_info).
def explts_search(self, query, pag): try: result = self.api.exploits.search(query, pag) except Exception as e: print(colors.FAIL + "\n [!] ERROR: " + colors.ENDC + str(e)) result = [] return result
Le pasamos los parámetros query y pag, hacemos la consulta con la API y devolvemos la variable result con la respuesta. En caso de error mostramos un mensaje y vaciamos la variable result.
def explts_info(self, res, sfile): if sfile is None: i = 0 for r in res['matches']: print("\n [+]" + colors.INFO + " ID: " + colors.ENDC + str(r.get('_id'))) print(" [-]" + colors.INFO + " Author: " + colors.ENDC + r.get('author')) print(" [-]" + colors.INFO + " Description: " + colors.ENDC + r.get('description')) print(" [-]" + colors.INFO + " Source: " + colors.ENDC + r.get('source')) print(" [-]" + colors.INFO + " Platform: " + colors.ENDC + r.get('platform')) print(" [-]" + colors.INFO + " Type: " + colors.ENDC + r.get('type')) print(" [-]" + colors.INFO + " Port: " + colors.ENDC + str(r.get('port'))) print(" [-]" + colors.INFO + " CVE: " + colors.ENDC + str(r.get('cve'))) print(" [-]" + colors.INFO + " Date: " + colors.ENDC + r.get('date')) i += 1 if i == 3: raw_input("\npress enter to continue...") i = 0 else: with open(sfile, "w") as f: for r in res['matches']: f.write("\n\n [+] ID: " + str(r.get('_id'))) f.write("\n [-] Author: " + r.get('author')) f.write("\n [-] Description: " + r.get('description')) f.write("\n [-] Source: " + r.get('source')) f.write("\n [-] Platform: " + r.get('platform')) f.write("\n [-] Type: " + r.get('type')) f.write("\n [-] Port: " + str(r.get('port'))) f.write("\n [-] CVE: " + str(r.get('cve'))) f.write("\n [-] Date: " + r.get('date')) print(" [i] " + colors.GREEN + "File saved!!\n" + colors.ENDC)
No hay mucho que decir que no hayamos visto antes, le pasamos el resultado devuelto por la función anterior, recorremos el diccionario matches y mostramos o guardamos la información dependiendo de si se ha indicado un archivo o no.
Con la última opción que vamos a ver podemos mostrar o guardar solo los campos elegidos en el resultado de un search, me explico, si usamos search para hacer una búsqueda con el script, el resultado nos muestra varios campos como pueden ser ip, port, country, city, etc. Pues mediante esta opción indicamos la información que nos interesa para mostrar o guardar. En un principio lo hice con idea de poder crear por ejemplo una lista de ips con ciertos puertos o servicios.
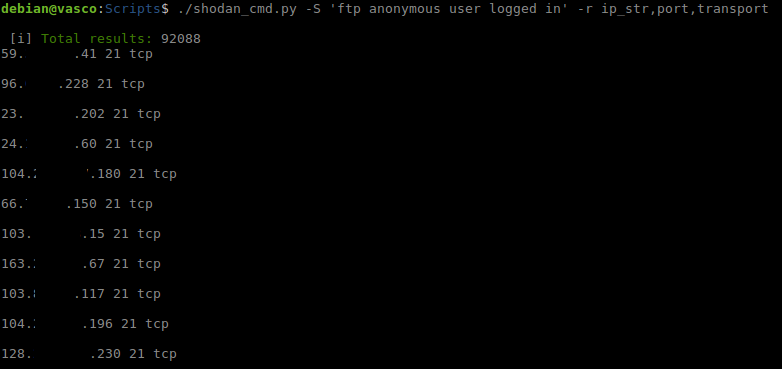 Opción Report.
Opción Report.
def report(self, res, field, sfile): loc = ['longitude', 'latitude', 'country_name', 'city'] if sfile is None: for r in res['matches']: if "," in field: lfield = field.split(",") for f in lfield: if f in loc: print(str(r['location'][f])), else: print(str(r.get(f))), print("\n") else: if field in loc: print(str(r['location'][field])) else: print(str(r.get(field))) else: with open(sfile, 'w') as f: for r in res['matches']: if "," in field: lfield = field.split(",") for fl in lfield: if fl in loc: f.write(str(r['location'][fl])) f.write(",") else: f.write(str(r.get(fl))) f.write(",") f.write("\n") else: if field in loc: f.write("\n " + str(r['location'][field])) else: f.write("\n " + str(r.get(field))) print("\n [i] " + colors.GREEN + "File saved!!\n" + colors.ENDC)
Le pasamos los parámetros res que es la salida de la consulta hecha con search, field es el campo o campos que nos interesan y sfile en caso de que vayamos a guardar dicha información en un archivo.
- Linea 1: es una lista con campos que a su vez están contenidos en un diccionario llamado location.
- Linea 2: en caso de que no se haya indicado un archivo…
- Linea 3: bucle que recorre cada diccionario contenido en matches.
- Linea 4: comprobamos si hay una coma en la variable field, lo que quiere decir que se han indicado mas de un campo.
- Linea 5: separamos los campos con .split y los guardamos en la lista lfield.
- Linea 6: por cada campo en la lista…
- Linea 7 – 10: comprueba si se encuentra en la lista loc para mostrarlo de una forma u otra.
- Linea 12 – 16: en caso de haber indicado solo un campo no es necesario usar split, simplemente comprobamos si se encuentra en la lista loc para actuar en consecuencia.
- Linea 17… : esta parte del código es igual que la anterior con la diferencia que ahora escribimos los datos en el archivo indicado.
Hasta aquí la entrada de hoy, recordar que no soy un experto programador y el script tendrá algunos fallos o mejor forma de hacer las cosas, se agradece todo tipo de opiniones y mejoras.
Un saludo.