
Hola secuaces:
Esta vez no vengo a contaros ninguna historia, (y no es por falta de ganas). Huelga decir que no puedo, ni con las mentiras, ni con los embustes. Vamos directos al ‘turrón’ 🙁
En esta ocasión, quiero trabajar con Bulk Extractor, desarrollado por Digital Corpora, que es un programa capaz de extraer información sensible de un fichero de imagen, un archivo o un directorio. Es capaz de encontrar y extraer direcciones URL, direcciones IP, direcciones de correo electrónico, números de tarjeta de crédito… Estos datos que extrae, posteriormente, pueden servirnos para seguir la investigación, según sea el caso, con otras herramientas. Por ejemplo, OSRFramework, de la que hay muy buen material, Maltego, https://who.is, por citar alguna.
Puede trabajar sobre Mac OS, Windows y Linux, y dispone de interfaz gráfica y línea de comandos. Podemos descargarla desde su sitio oficial. Y también tienen disponible unas imágenes de ejemplos sobre las que realizar pruebas, que se pueden descargar, igualmente, desde su sitio oficial.
Procesa datos comprimidos, completos o dañados. Realiza labores de carving, aunque, en lo personal, recomiendo usar otras herramientas. Crea listas de palabras que puede ser útil para generar un diccionario y efectuar el cracking de contraseñas. Quizás, el punto que más me llama la atención, sea el hecho de que crea histogramas con los datos que extrae. Por definirlo de otra forma, nos muestra un contador.
Cuando encuentra un dato, escribe la salida a un fichero, que contiene, entre otros datos, el ‘offset‘ en el que se encuentra ese dato. Trabaja en dos fases: primero, extrae, y luego crea el histograma.
También es cierto que no está exenta de falsos positivos, por lo que habría que contrastar la información extraída.
Dado que esta entrada va a ser bastante larga, y vamos a trabajar con ‘patterns’, (patrones), he optado por incluir un enlace con cada línea de la consola a https://explainshell.com, para que podáis ver su correspondiente explicación.
Si queréis aprender sobre patrones, hay una persona a la que debéis seguir. Se trata, ni más ni menos, que del ‘Señor de Suricata’, @seguridadyredes. Todo un maestro en patrones, además de en otros quehaceres. Podéis ver algunos de sus ejemplos con ‘grep’ aquí.
Tenemos estas evidencias: un volcado de memoria y un fichero ‘Pagefiles.sys’, que podemos ver con un simple ‘ls‘
![]()
Como no puede ser de otra forma, comenzamos por identificar los ficheros de los que disponemos, mediante ‘file‘

Y, para no perder las buenas costumbres, calculamos su firma digital en formato sha1

Antes de empezar a trabajar con la herramienta, vamos a mirar qué ayuda nos ofrece
bulk_extractor -h

Podemos ver que los únicos parámetros requeridos son, el fichero de imagen y un directorio de salida.

Podemos ajustar algunos parámetros.


Podemos ver sus opciones configurables, con una breve descripción.
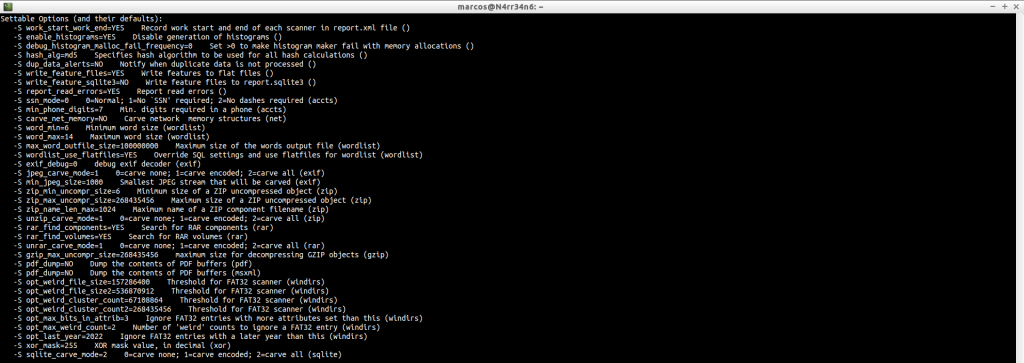
Podemos, con el parámetro ‘-e’, habilitar algún escáner que esté deshabilitado.

Y podemos, con el parámetro ‘-x’, deshabilitar algún escáner que no nos interese usar.

Vamos a ver su uso básico, que es más que suficiente para empezar.
Invocamos la herramienta, le indicamos un directorio de salida y le decimos qué fichero tiene que analizar.
bulk_extractor -o /home/marcos/Evidencias/Bulk_PC-20170427_/ /home/marcos/Evidencias/PC-20170427.dmp

Una vez que termina, nos presenta un pequeño resumen en pantalla.

Y ahora listamos la información que ha sido extraída, que no es poca.

Como se puede ver, en este caso, hay dos directorios, un fichero ‘.pcap’ y unos cuantos ficheros de texto, ‘.txt’
Pero, en qué formato están esos ficheros de texto. Es importante saberlo, así que usamos ‘file’ con ellos. Algunos serán fácilmente legibles. Otros, no tanto.
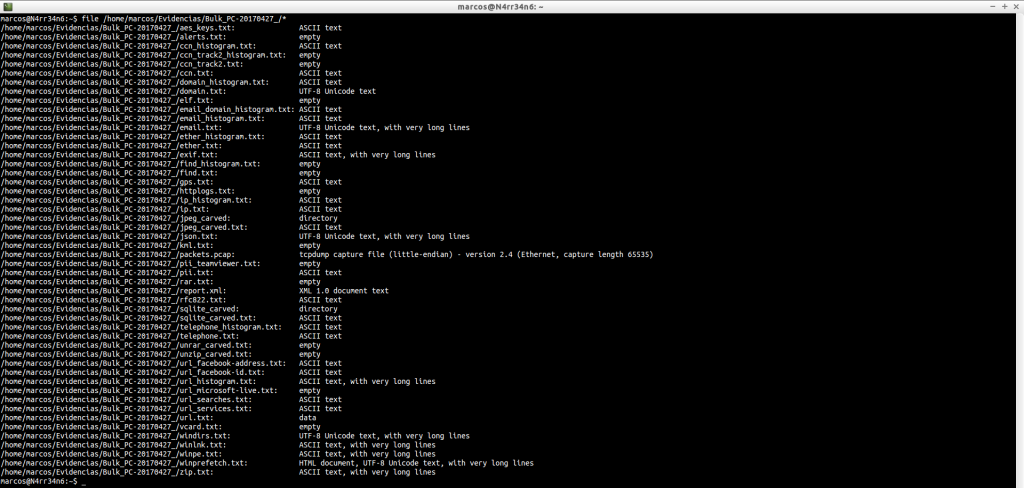
Muy bien. Muy bonito todo. Pero, ¿Qué nos ha extraído? Vemos ficheros de texto en formato ASCII, UTF-8, XML HTML y data.
Vamos a ver qué nos ha extraído cada uno de ellos, según su orden de aparición, y qué podemos hacer con ellos. Y para ello emplearemos a ‘cat‘.
aes_keys.txt: Claves con el algoritmo de cifrado AES, que se encuentran en memoria.

ccn_histogram.txt: Número de tarjeta de crédito, (Credits Cards Numbers).
cat /home/marcos/Evidencias/Bulk_PC-20170427_/ccn_histogram.txt

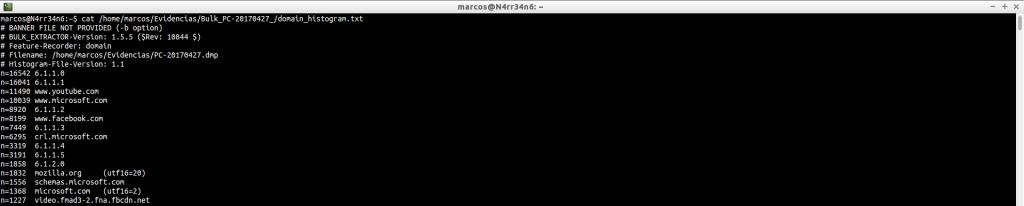
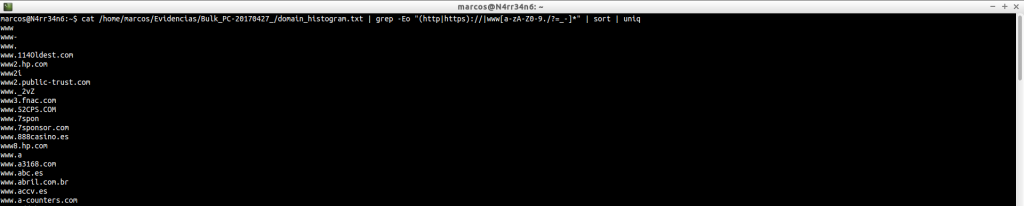
domain_histogram.txt: Un histograma de los dominios encontrados en el fichero de imagen, con su correspondiente contador, que es el bloque numérico de la izquierda. Muchos dominios formarán parte del propio Sistema Operativo. Otros, nos darán información sobre la actividad de los usuarios en la máquina y sobre los sitios que se visitan con mayor frecuencia. Este fichero nos va a dar información más concreta, en principio, que el fichero ‘domain.txt’, que también genera. Pero, como se puede ver, hay datos para todos los gustos y colores, además de una bonita lista de unos cientos, o miles, de dominios encontrados. ¿Qué podemos hacer al respecto?
cat /home/marcos/Evidencias/Bulk_PC-20170427_/domain_histogram.txt
Filtrar los datos. ¿Cómo? Usando ‘grep‘ o ‘egrep‘ y sus correspondientes ‘patterns’, (patrones). ¿No sabemos lo que es eso, o cómo usarlos? No importa. Podemos ‘perder el tiempo’ en buscarlos, y esperar que hagan lo que queremos. (Hay de todo).

O podemos invertir ese tiempo en saber cómo funcionan y crearlos o adaptarlos a nuestras necesidades. El único requisito es… saber qué queremos buscar.
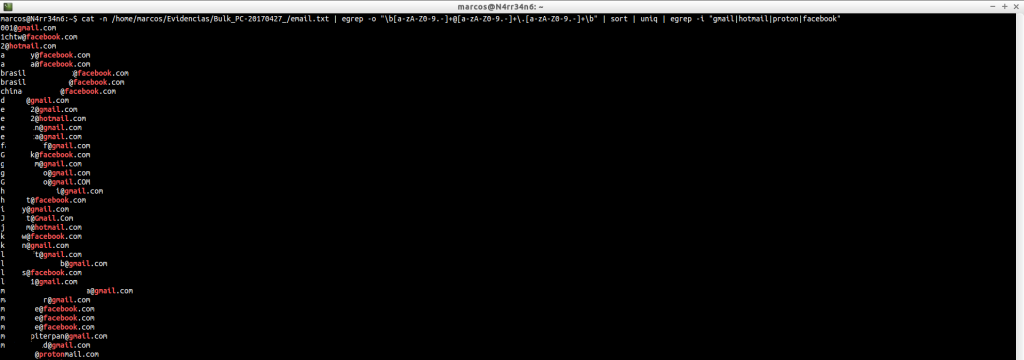
domain.txt: Proporciona una lista de todos los dominios, URLs y correos electrónicos. El bloque numérico de la izquierda corresponde al ‘offset’ donde se encuentra la información extraída. Le sigue el nombre del dominio y la URL.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/domain.txt | head

Como este fichero puede contener información muy interesante, debemos escudriñarlo bien. Y, como en el caso anterior, vamos a usar filtros de búsqueda.
Podemos buscar, únicamente, direcciones de correos electrónicos.
![]()
Y podemos afinar más esa búsqueda.

Y volver a afinarla, aún más, hasta que encontremos lo que estamos buscando
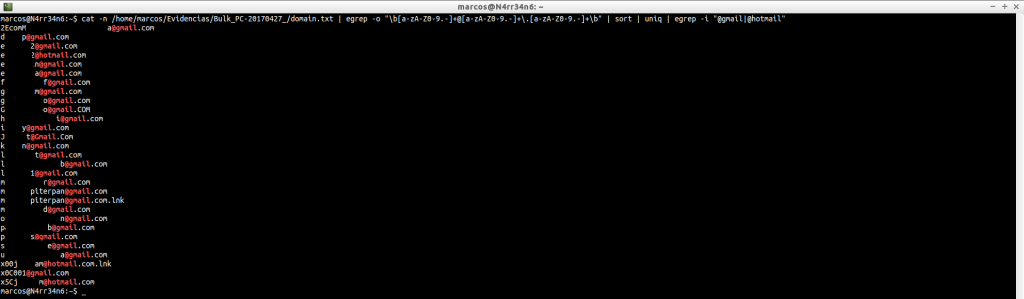
Podemos realizar filtrados muy básicos, y de forma individual, para buscar algunos sitios web
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/domain.txt | grep -i sex

cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/domain.txt | grep -i xxx

Podemos buscar sitios web, afinando mejor la búsqueda
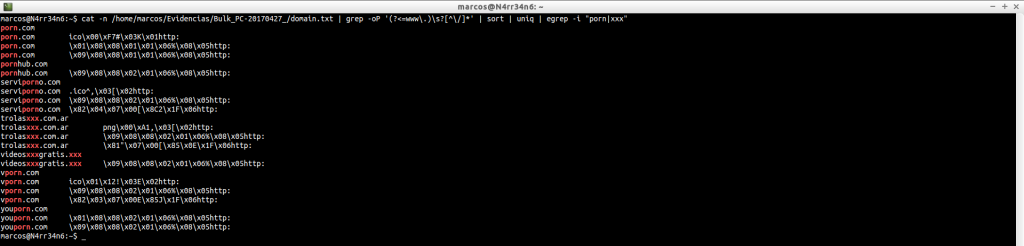
email_domain_histogram.txt: Muestra el dominio de las direcciones de correo más frecuentes

email_histogram.txt: Muestra las direcciones de correo electrónico más frecuentes.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/email_histogram.txt

email.txt: Extrae direcciones de correos electrónicos. Cabe destacar que este fichero contiene texto en formato UTF-16.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/email.txt

Como nos interesa extraer las direcciones email que contiene, vamos a afinar un poco más la búsqueda
![]()
Y todavía podríamos afinarla más
ether_histogram.txt: Proporciona un histograma de direcciones Ethernet que se encuentran en el fichero de imagen. Estas direcciones se pueden pasar, después, por sitios web que nos facilitan el fabricante de la tarjeta de red. Por citar alguno, https://macvendors.com/
cat /home/marcos/Evidencias/Bulk_PC-20170427_/ether_histogram.txt

ether.txt: Igual que en el caso anterior, proporciona una lista de direcciones Ethernet que se encuentran en el fichero de imagen, pero, en este caso, sin agrupar.

Pero si las ordenamos y le indicamos que no duplique contenido, nos coincidirá con las del caso anterior.

exif.txt: Nos muestra los metadatos de los ficheros, incluyendo la geolocalización, en caso de estar disponible.

gps.txt: Muestra la información de geolocalización de un usuario, que podremos consultar, posteriormente, con Google Maps.

ip_histogram.txt: Nos muestra un contador con las IPs, según su uso. Este fichero es más limpio que el que veremos ahora, ‘ip.txt’
cat /home/marcos/Evidencias/Bulk_PC-20170427_/ip_histogram.txt

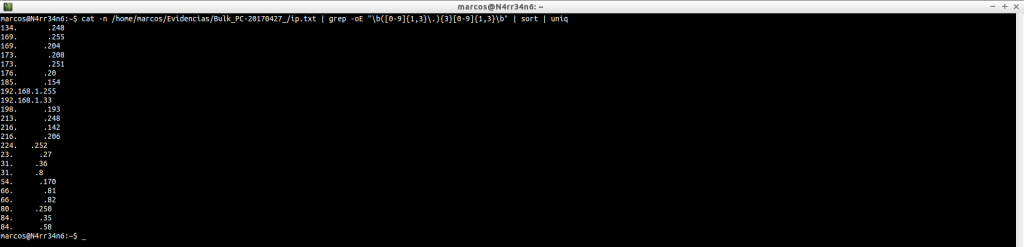
ip.txt: Nos muestra todas las direcciones IP que se han extraído del fichero de imagen. El carácter ‘L’ significa que se trata de una IP local y el carácter ‘R’ significa que se trata de una IP remota. Incluye un ‘checksum‘, (suma de verificación), como ‘-ok’ o ‘-bad’, para indicar los posibles falsos posisitivos.

Si queremos limpiar algo de ruido, podemos filtrar mejor los resultados
jpeg_carved: Este el directorio donde se han extraído los ficheros de imagen
ls -s /home/marcos/Evidencias/Bulk_PC-20170427_/jpeg_carved
ls -s /home/marcos/Evidencias/Bulk_PC-20170427_/jpeg_carved/000/

Que podemos comprobar. Ello no indica que estén completos, sino que se ha encontrado esa cabecera.
file /home/marcos/Evidencias/Bulk_PC-20170427_/jpeg_carved/000/*

jpeg_carved.txt: Esta es la lista de todos los ficheros en formato ‘JPEG‘ que han sido extraídos.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/jpeg_carved.txt

json.txt: Los ficheros ‘json‘ suelen ser usados para investigaciones de malware y el análisis de aplicaciones basadas en web, y por lo tanto, pueden contener información muy útil. Pero como podemos ver, si no está bien formado, tenemos que buscar la información que deseamos por otros métodos.
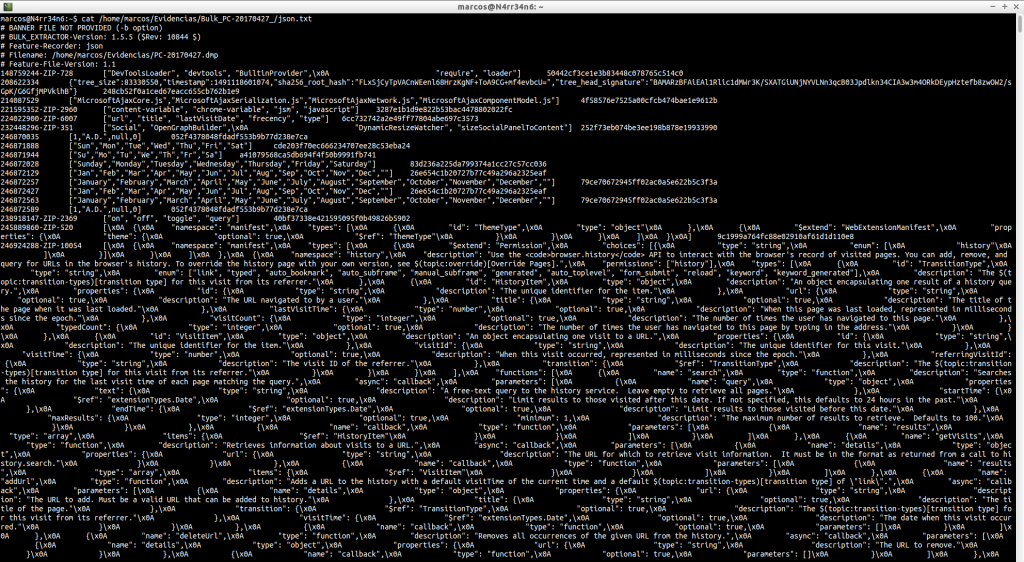
Podemos buscar, como hemos hecho anteriormente, direcciones de email.
![]()
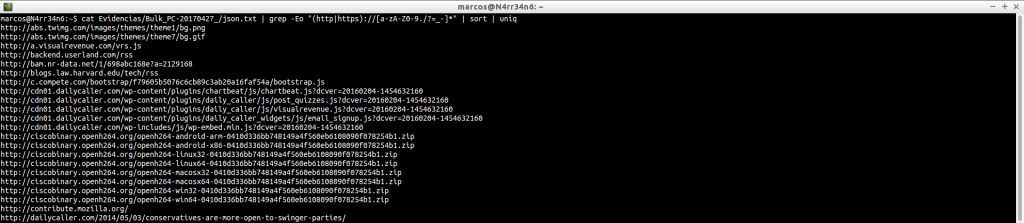
Buscar direcciones IP con un tipo de filtro
cat Evidencias/Bulk_PC-20170427_/json.txt | grep -oE «\b([0-9]{1,3}\.){3}[0-9]{1,3}\b» | sort | uniq
![]()
O con otro. Todo depende de lo que queramos, en la exactitud de la búsqueda.
![]()
Buscar sitios web
![]()
Busquemos lo que busquemos, tenemos que tener claro qué es lo que deseamos buscar, para conseguir afinar al máximo posible los resultados que queremos obtener. Aquí podemos ver cómo, un mínimo parámetro, nos puede dar una URL incompleta…
O una URL completa.

Y podemos seguir afinando los resultados, tal y como queramos.

Y no cuesta nada entender cómo funcionan los patrones, por ejemplo, para buscar direcciones de correo electrónico de forma correcta, y sin complicaciones.

packets.pcap: Se trata de un fichero que contiene paquetes, información, de red.

Estos paquetes pueden ser analizados para extraer información, por ejemplo, con Wireshark o Tshark. También se puede realizar ‘carving’ sobre ellos. Existe un sitio muy bueno, pero que muy bueno, sobre el análisis de tráfico de red, que pertenece, casualmente, al ‘Señor de Suricata’: https://seguridadyredes.wordpress.com/
tshark -r /home/marcos/Evidencias/Bulk_PC-20170427_/packets.pcap -Y http

pii.txt: Información de identificación personal incluyendo fechas de nacimiento y números sociales

report.xml: Se trata de un fichero de reporte que contiene todo el proceso de ejecución.

rfc822.txt: Proporciona, principalmente, encabezados de correo electrónico y encabezados HTTP, que están en un formato especificado por RFC822, el estándar de mensajes de Internet
cat /home/marcos/Evidencias/Bulk_PC-20170427_/rfc822.txt | head
cat /home/marcos/Evidencias/Bulk_PC-20170427_/rfc822.txt | tail


Aquí, podríamos empezar por ordenar los resultados según su fecha.

O podemos buscar, como hemos hecho en otras ocasiones, direcciones IP.

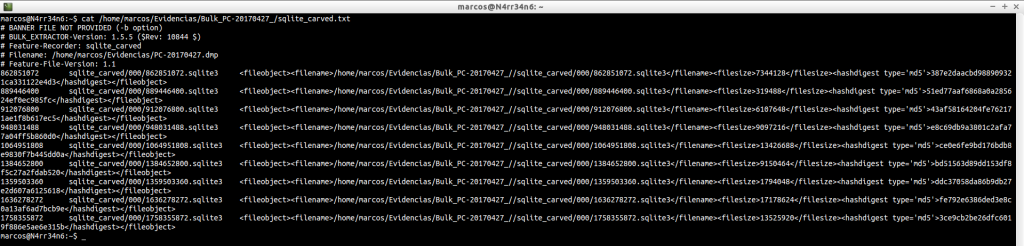
sqlite_carved: Esto es un directorio que contiene bases de datos, que ha recuperado, en formato SQLite
ls -s /home/marcos/Evidencias/Bulk_PC-20170427_/sqlite_carved
ls -s /home/marcos/Evidencias/Bulk_PC-20170427_/sqlite_carved/000/

sqlite_carved.txt: Fichero que contiene un listado con las bases de datos que ha conseguido extraer.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/sqlite_carved.txt
telephone_histogram.txt: Lista de número de teléfono que han sido encontrados, con un contador de frecuencia. Esta información suele dar muchos falsos positivos.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/telephone_histogram.txt

telephone.txt: Muestra el listado completo de número de teléfono que han sido encontrados.
url_facebook-address.txt: Nos muestra las direcciones de Facebook que han sido visitadas.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_facebook-address.txt

Y las podemos ordenar como queramos.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_facebook-address.txt | sort | uniq

uel_facebook-id.txt: Nos muestra los ID, (identificadores únicos), de los perfiles que han sido visitados en Facebook.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_facebook-id.txt

Que podremos filtrar como deseemos.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_facebook-id.txt | sort | uniq

url_histogram.txt: Nos proporciona un histograma con todas las URLs que han sido visitadas.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_histogram.txt | head
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_histogram.txt | tail


url_searches.txt: Nos porporciona un histograma con las búsquedas que ha encontrado y que se han hecho en el navegador.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_searches.txt

url_services.txt: Otro fichero que nos proporciona direcciones web que han sido encontradas en el fichero de imagen.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_services.txt

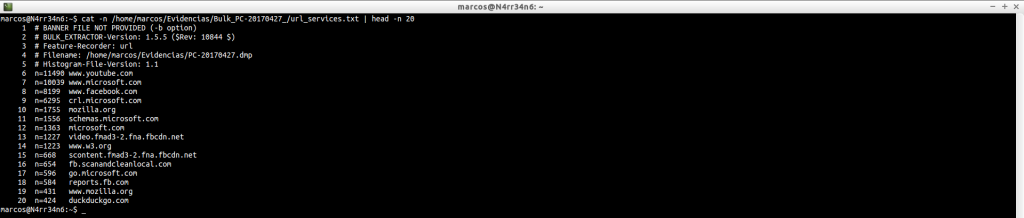
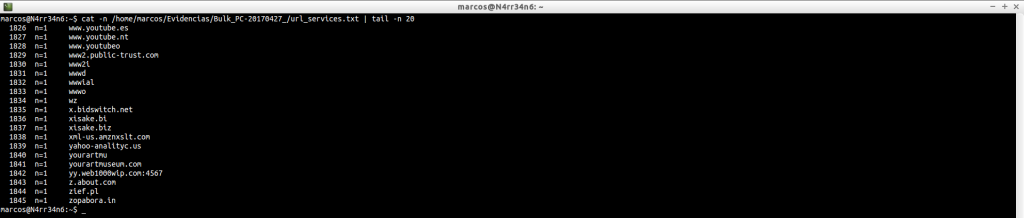
Podemos hacernos una idea de la información que contiene.
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/url_services.txt | head -n 20
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/url_services.txt | tail -n 20
url.txt: Fichero que contiene todas las direcciones URL halladas en el fichero de imagen. Contiene texto en formato UTF-16. Y arroja información muy útil, para saber qué ha sido visitado.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url.txt | head
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url.txt | tail


Aquí podemos usar filtros muy interesantes, para, en primer lugar, hacer bien legible la informaicón. Este, por ejemplo, para buscar sitios web, sin que se repitan los resutlados.

O este otro, para buscar direcciones web que contengan ciertas palabras.
cat -n Evidencias/Bulk_PC-20170427_/url.txt | egrep -Eo «(http|https|www)://[a-zA-Z0-9./%&?=_-]*» | sort | uniq | egrep -i «xxx|porn|photo|video|jpg|jpeg» | head
cat -n Evidencias/Bulk_PC-20170427_/url.txt | egrep -Eo «(http|https|www)://[a-zA-Z0-9./%&?=_-]*» | sort | uniq | egrep -i «xxx|porn|photo|video|jpg|jpeg» | tail


O podemos, simplemente, indicarle que nos muestre el número de coincidencias con esas palabras.
![]()
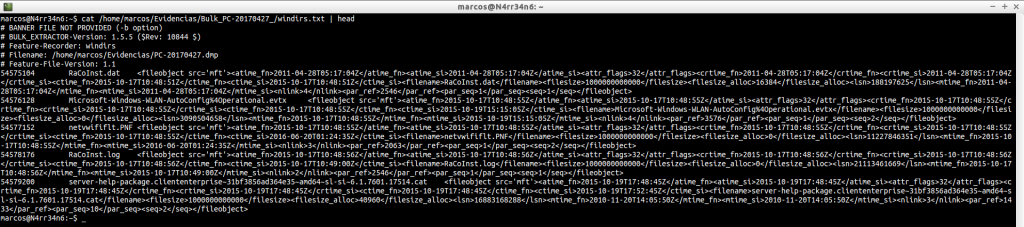
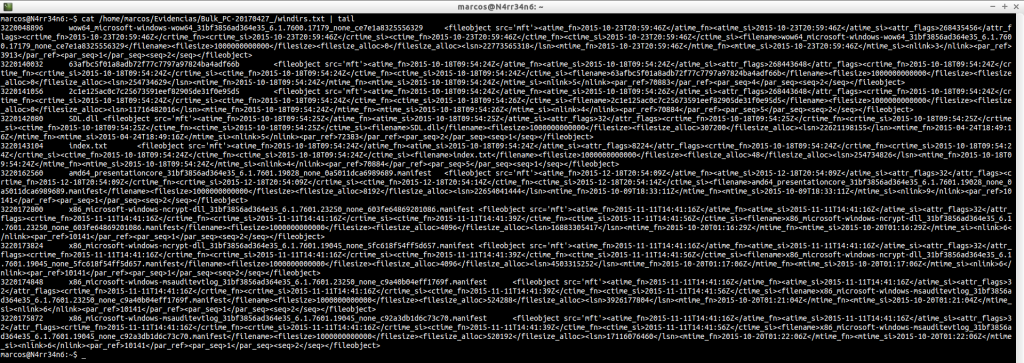
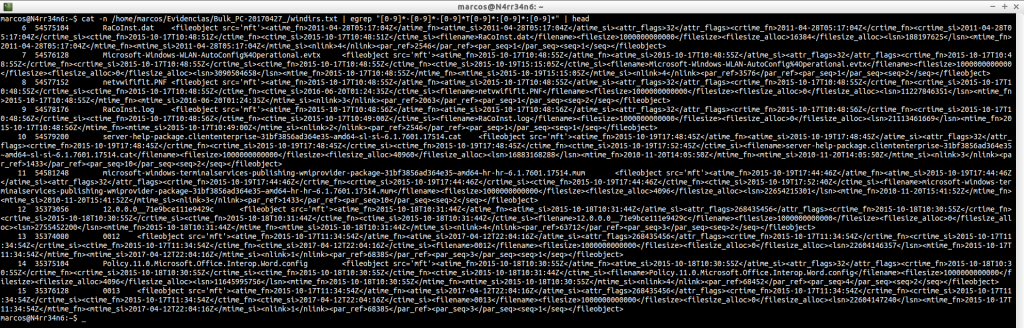
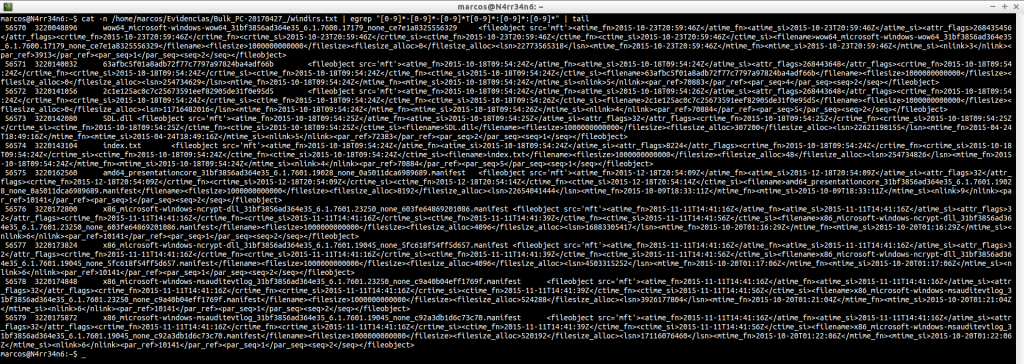
windirs.txt: Nos muestra las entradas de directorios de los Sistemas Windows. Su lectura se puede hacer bastante pesada.
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/windirs.txt | head
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/windirs.txt | tail
Pero podríamos, por ejemplo, ordenarlas estableciendo un orden cronológico
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/windirs.txt | egrep «[0-9]*-[0-9]*-[0-9]*T[0-9]*:[0-9]*:[0-9]*» | head
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/windirs.txt | egrep «[0-9]*-[0-9]*-[0-9]*T[0-9]*:[0-9]*:[0-9]*» | tail
winlnk.txt: Encuentra enlaces simbólicos, rutas, en el fichero de imagen. Muy útil para buscar nombres de ficheros, unidades, directorios, …
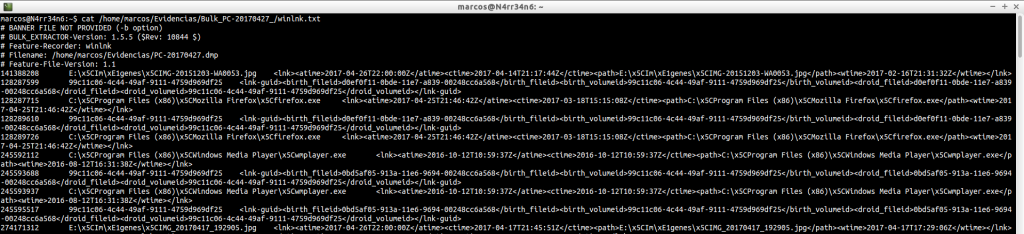
Y podemos afinar el resultado, buscando coincidencias con rutas
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/winlnk.txt | egrep -ion «[a-zA-Z]:[\].*.*» | head
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/winlnk.txt | egrep -ion «[a-zA-Z]:[\].*.*» | tail


Y aún podemos filtrar más los resutlados, indicándole, por ejemplo, que nos muestre únicamente un tipo de ficheros.
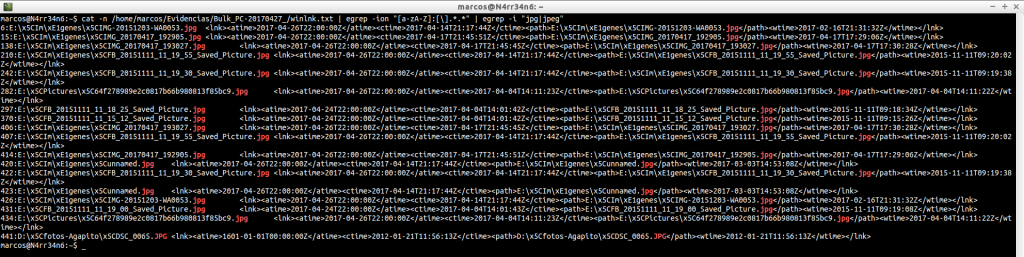
winpe.txt: Este fichero muestra ejecutables que están relaciones con el entorno de instalación de Windows. Se suele examinar cuando el caso tiene relación con algún tipo de malware.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winpe.txt | head
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winpe.txt | tail
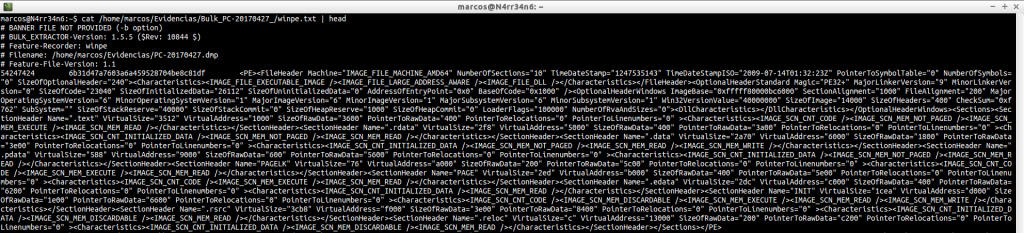

winprefetch.txt: Lista todos los ficheros prefetch del Sistema, incluidos los eliminados.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winprefetch.txt

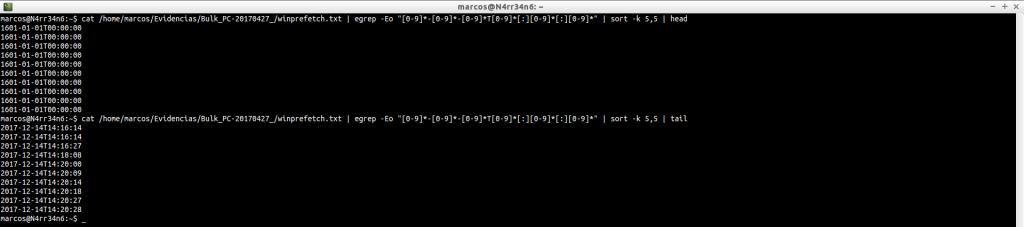
En este caso, podemos realizar filtros por fechas.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winprefetch.txt | egrep -Eo «[0-9]*-[0-9]*-[0-9]*T[0-9]*[:][0-9]*[:][0-9]*» | sort -k 5,5 | head
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winprefetch.txt | egrep -Eo «[0-9]*-[0-9]*-[0-9]*T[0-9]*[:][0-9]*[:][0-9]*» | sort -k 5,5 | tail
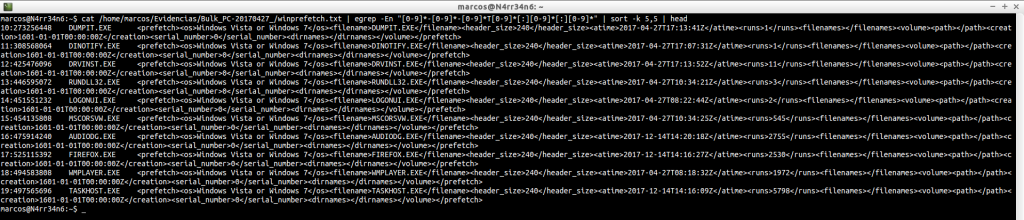
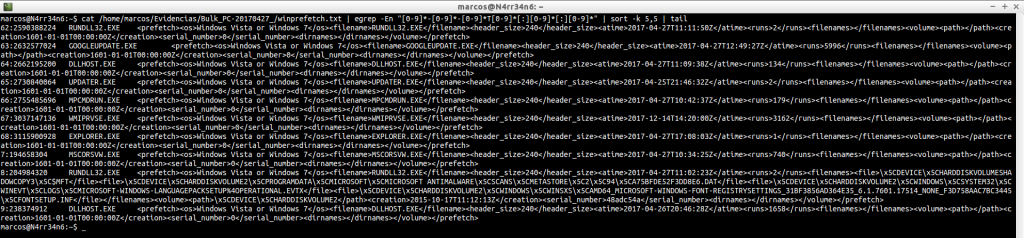
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winprefetch.txt | egrep -En «[0-9]*-[0-9]*-[0-9]*T[0-9]*[:][0-9]*[:][0-9]*» | sort -k 5,5 | head
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winprefetch.txt | egrep -En «[0-9]*-[0-9]*-[0-9]*T[0-9]*[:][0-9]*[:][0-9]*» | sort -k 5,5 | tail
zip.txt: Examina y muestra el contenido de los ficheros ‘.zip’ que ha encontrado.
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/zip.txt | head
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/zip.txt | tail

Toda esta información es la que se ha obtenido, o se puede obtener, de, por ejemplo, un volcado de memoria como el que hemos visto. Pero, ¿Se pueden analizar más ficheros? Tal y como hemos mencionado al principio, (muy arriba), sí. Podemos procesar, de igual manera, un fichero ‘Pagefile.sys’, por ejemplo.
bulk_extractor -o /home/marcos/Evidencias/Pagefile_PC-20170427_/ /home/marcos/Evidencias/PC-20170427-Pagefile.sys


Y podemos observar qué cantidad de información se puede llegar a obtener.

CONCLUSIONES
Bulk Extractor es una herramienta capaz de extraer una ingente cantidad de información. En este caso, en el que pretendía mostraros ‘el poder’ de este software, no buscaba nada en concreto. Pero, como cada caso es un mundo, y no existen dos análisis iguales, tenemos que tener muy claro qué es lo que queremos buscar y debemos preocuparnos por saber cómo buscarlo, para eso están los patrones de búsqueda. De nada nos sirve tener toda esta información si no somos capaces de procesarla, (como humanos).
Esto es todo, por ahora. Nos leemos en la siguiente entrada. Se despide este minion, entregado y leal, de vosotros… por ahora.
Marcos @_N4rr34n6_
Un comentario en «¿Quién es el Señor ‘X’? Averigüémoslo con #BulkExtractor y #Patterns de #Egrep (Somos lo que navegamos)»
Los comentarios están cerrados.