
Hi Minions:
This time I do not come to tell you any story, (and not for lack of desire). Suffice it to say that I can not, neither with lies nor with scams. Let’s go straight to the ‘nougat’ 🙁
This time, I want to work with Bulk Extractor, developed by Digital Corpora, which is a program capable of extracting sensitive information from an image file, a file or a directory. It is able to find and extract URLs, IP addresses, e-mail addresses, credit card numbers … This data extracted, later can serve us to follow the investigation, as the case may be, with other tools. For example, OSRFramework, of which there is very good material, Maltego, https://who.is, to name a few.
It can work on Mac OS, Windows and Linux, and has graphical interface and command line. We can download it from its official site. And they also have available images of examples on which to perform tests, which can also be downloaded from its official site.
Processes data compressed, complete or corrupted. It works with carving, although, personally, I recommend using other tools. Create word lists that can be useful for generating a dictionary and cracking passwords. Perhaps the point that strikes me most is the fact that it creates histograms with the data it extracts. To define it in another way, it shows a counter.
When it finds a data, it writes the output to a file, which contains, among other data, the ‘offset‘ in which that data is found. It works in two phases: first, extract, and then create the histogram.
It is also true that it is not exempt from false positives, so it would be necessary to contrast the extracted information.
Since this post going to be quite long, and we are going to work with ‘patterns’, I have chosen to include a link with each line of the console to https://explainshell.com, so that you can see its corresponding Explanation.
If you want to learn about patterns, there is one person you should follow. It is, neither more nor less, than the ‘Lord of Suricata’,@seguridadyredes. A master in patterns, in addition to other chores. You can see some of their examples with ‘grep’ here.
We have these evidences: a memory dump and a file ‘Pagefiles.sys’, that we can see with a simple ‘ls‘.
![]()
As it can not be otherwise, we start by identifying the files we have, with ‘file‘.

And, in order not to lose the good habits, we calculate your digital signature in sha1 format.

Before we start working with the tool, let’s look at what help offers us.
bulk_extractor -h

We can see that the only required parameters are, the image file and an output directory.

We can adjust some parameters.


We can see your configurable options, with a brief description.
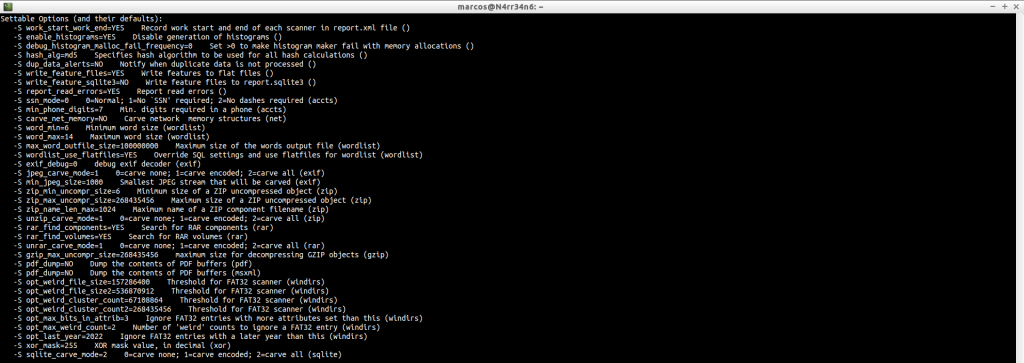
We can, with the parameter ‘-e’, enable some scanner that is disabled.

And we can, with the parameter ‘-x’, disable some scanner that we do not want to use.

Let’s see its basic usage, which is more than enough to start.
We invoke the tool, tell you an output directory and tell you what file you have to analyze.
bulk_extractor -o /home/marcos/Evidencias/Bulk_PC-20170427_/ /home/marcos/Evidencias/PC-20170427.dmp

Once it’s over, it gives us a little on-screen summary.

And now we list the information that has been extracted, which is not small.

As you can see, in this case, there are two directories, a ‘.pcap’ file and a few text files, ‘.txt’
But, in what format are these text files? It’s important to know, so we use ‘file’ with them. Some will be easily readable. Others, not so much.
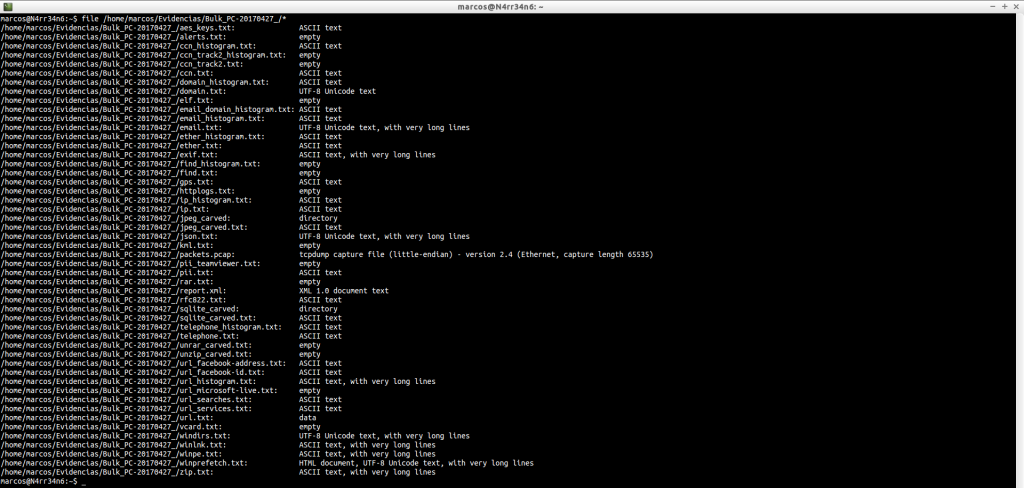
Very good. Very nice everything. But, what has he extracted? We see text files in ASCII, UTF-8, XML HTML and data format.
Let’s see what each of them has extracted, according to their order of appearance, and what we can do with them. And for this we will use ‘cat‘.
aes_keys.txt: Keys with the AES encryption algorithm, which are in memory.

ccn_histogram.txt: Credit card number
cat /home/marcos/Evidencias/Bulk_PC-20170427_/ccn_histogram.txt

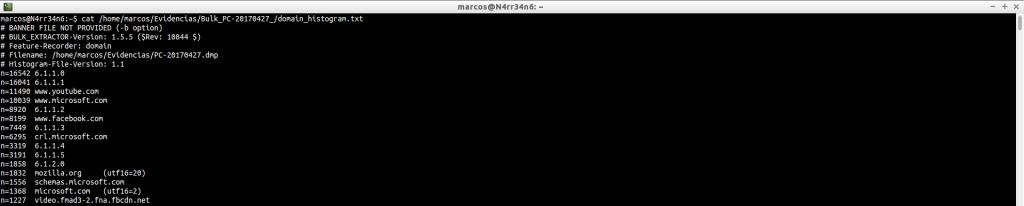
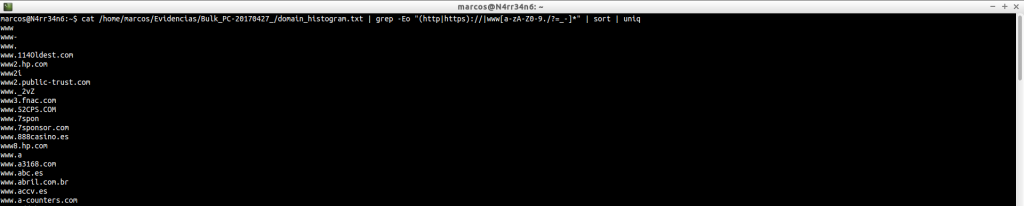
domain_histogram.txt: A histogram of the domains found in the image file, with its corresponding counter, which is the numeric block on the left. Many domains will be part of the Operating System itself. Others will give us information about the activity of the users in the machine and on the sites that are visited more frequently. This file will give us more specific information, in principle, than the file ‘domain.txt’, which also generates. But, as you can see, there are data for all tastes and colors, plus a nice list of a few hundred, or thousands, of domains found. What can we do about it?
cat /home/marcos/Evidencias/Bulk_PC-20170427_/domain_histogram.txt
Filter the data. How? Using ‘grep‘ or ‘egrep‘ and their corresponding ‘patterns’. Do not we know what that is, or how to use them? Does not matter. We can ‘waste time’ on finding them, and expect them to do what we want… (There is everything).

Or we can invest that time in knowing how they work and create or adapt them to our needs. The only requirement is … to know what we want to look for.
domain.txt: Provides a list of all domains, URLs and emails. The numerical block on the left corresponds to the offset where the extracted information is located. It is followed by the domain name and the URL.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/domain.txt | head

As this file may contain very interesting information, we must scrutinize it well. And, as in the previous case, we will use search filters.
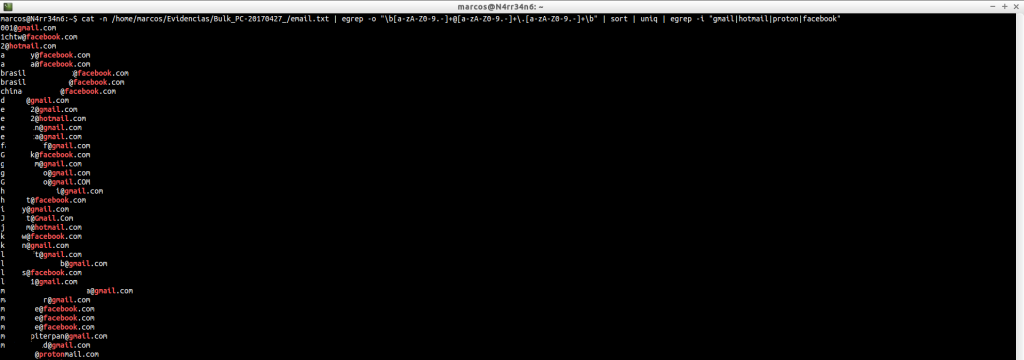
We can search for e-mail addresses.
![]()
And we can refine that search.

And refine it, even more, until we find what we are looking for
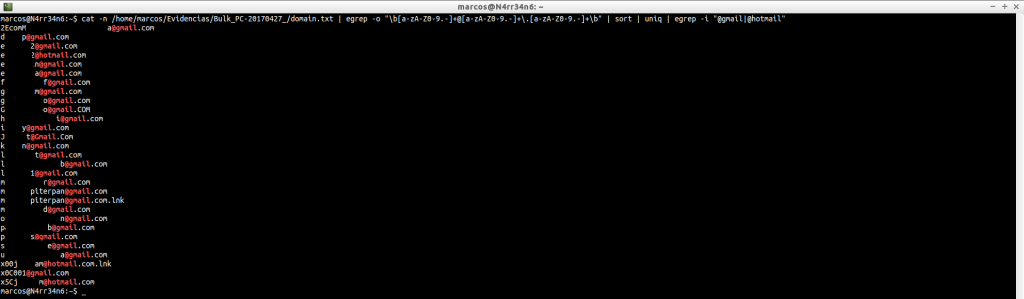
We can do very basic filtering, and individually, to search some websites
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/domain.txt | grep -i sex

cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/domain.txt | grep -i xxx

We can search websites, improving the search
email_domain_histogram.txt: Displays the domain of the most frequent email addresses

email_histogram.txt: Displays the most frequently used email addresses.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/email_histogram.txt

email.txt: Extract addresses from emails. Note that this file contains text inUTF-16 format.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/email.txt

As we are interested in extracting the email addresses it contains, let’s narrow down the search a bit more
![]()
And we could still refine the search more
ether_histogram.txt: Provides a histogram of Ethernet addresses that are in the image file. These addresses can then be passed, after, through websites that provide us the manufacturer of the network card. To cite some, https://macvendors.com/
cat /home/marcos/Evidencias/Bulk_PC-20170427_/ether_histogram.txt

ether.txt: As in the previous case, it provides a list of Ethernet addresses that are in the image file, but in this case, without clustering.

But if we order them and tell them not to duplicate content, it will match those of the previous case.

exif.txt: It shows us the metadata of the files, including the geolocation, if it is available.

gps.txt: It shows the geolocation information of a user, which we can later consult with Google Maps.

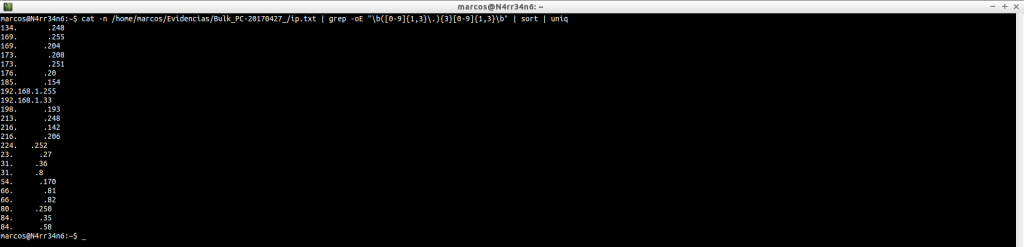
ip_histogram.txt: It shows us a counter with the IPs, according to its use. This file is cleaner than the one we will see now, ‘ip.txt’
cat /home/marcos/Evidencias/Bulk_PC-20170427_/ip_histogram.txt

ip.txt: It shows us all the IP addresses that have been extracted from the image file. The ‘L’ character means that it is a local IP and the ‘R’ character means that it is a remote IP. It includes a ‘checksum‘, such as ‘-ok’ or ‘-bad’, to indicate possible false positives.

If we want to clean some noise, we can better filter the results
jpeg_carved: This is the directory where the image files have been extracted
ls -s /home/marcos/Evidencias/Bulk_PC-20170427_/jpeg_carved
ls -s /home/marcos/Evidencias/Bulk_PC-20170427_/jpeg_carved/000/

That we can check. This does not indicate that they are complete, it means that this header has been found.
file /home/marcos/Evidencias/Bulk_PC-20170427_/jpeg_carved/000/*

jpeg_carved.txt: This is the list of all files in ‘JPEG‘ format that have been extracted.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/jpeg_carved.txt

json.txt: ‘Json‘ files are often used for malware research and analysis of web-based applications, and therefore may contain very useful information. But as we can see, if it is not well formed, we have to look for the information we want by other methods.
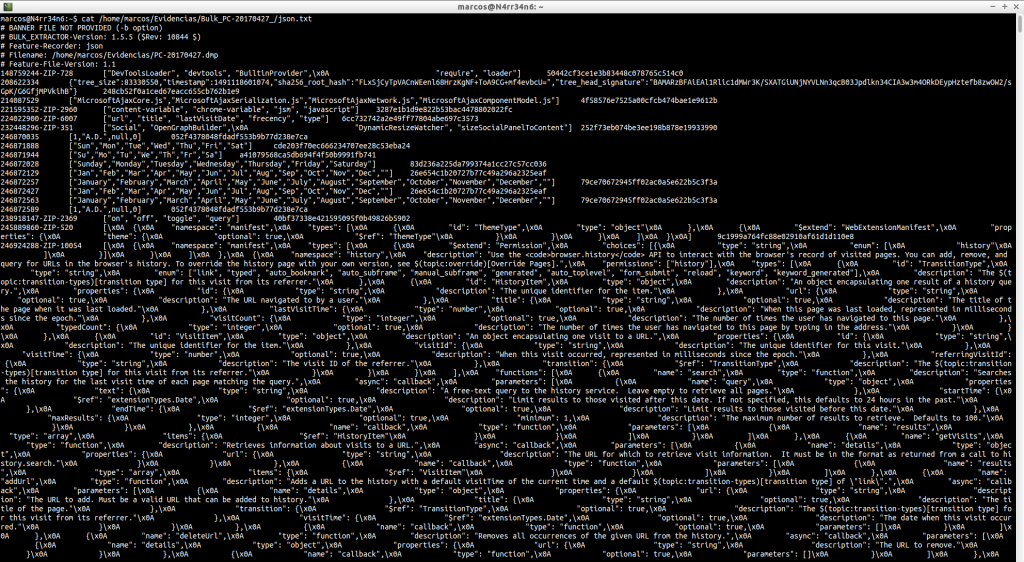
We can search, as we have done previously, email addresses.
![]()
Find IP addresses with a filter type
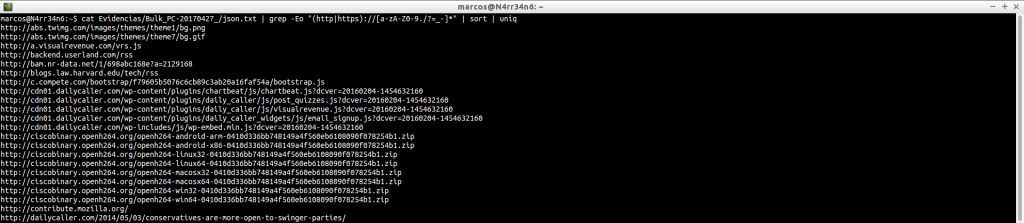
cat Evidencias/Bulk_PC-20170427_/json.txt | grep -oE «\b([0-9]{1,3}\.){3}[0-9]{1,3}\b» | sort | uniq
![]()
Or with another. Everything depends on what we want, on the accuracy of the search.
![]()
Search websites
![]()
We seek what we seek, we have to be clear. What it is that we want to look for? So that we can get the results we want. Here we can see how, with a minimum parameter, we can give with an incomplete URL…
Or a full URL.

And we can continue tuning the results, as we want.

And it costs nothing to understand how patterns work, for example, to search for e-mail addresses correctly, and without complications.

packets.pcap: It is a file containing packages, information, about the network.

These packages can be analyzed to extract information, for example, with Wireshark or Tshark. Carving can also be done on them. There is a very good site, but very good, on the analysis of network traffic, which belongs, incidentally, to the ‘Lord of Suricata’: https://seguridadyredes.wordpress.com/
tshark -r /home/marcos/Evidencias/Bulk_PC-20170427_/packets.pcap -Y http

pii.txt: Personally identifiable information including birth dates and social numbers

report.xml: It is a report file that contains the entire execution process.

rfc822.txt: It mainly provides e-mail headers and HTTP headers, which are in a format specified byRFC822, about the Internet Message Standard
cat /home/marcos/Evidencias/Bulk_PC-20170427_/rfc822.txt | head
cat /home/marcos/Evidencias/Bulk_PC-20170427_/rfc822.txt | tail


Here, we could begin by sorting the results according to their date.

Or we can search, as we have done on other occasions, IP addresses.

sqlite_carved: This is a directory containing databases, which you have retrieved, in SQLite format
ls -s /home/marcos/Evidencias/Bulk_PC-20170427_/sqlite_carved
ls -s /home/marcos/Evidencias/Bulk_PC-20170427_/sqlite_carved/000/

sqlite_carved.txt: File containing a list with the databases that have been extracted.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/sqlite_carved.txt
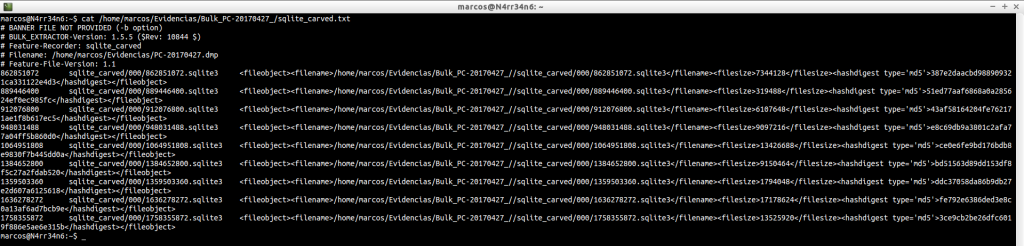
telephone_histogram.txt: List of phone number that have been found, with a frequency counter of use. This information often gives many false positives.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/telephone_histogram.txt

telephone.txt: It shows the complete list of telephone numbers that have been found.
url_facebook-address.txt: It shows us the Facebook addresses that have been visited.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_facebook-address.txt

And we can order them any way we want.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_facebook-address.txt | sort | uniq

uel_facebook-id.txt: It shows us the IDs (unique identifiers) of the profiles that have been visited on Facebook.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_facebook-id.txt

That we can filter as we wish.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_facebook-id.txt | sort | uniq

url_histogram.txt: It provides us with a histogram with all the URLs that have been visited.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_histogram.txt | head
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_histogram.txt | tail


url_searches.txt: It provides us with a histogram with the searches that it has found and that have been done in the browser.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_searches.txt

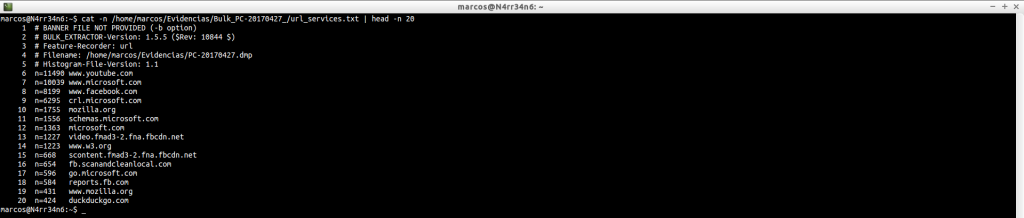
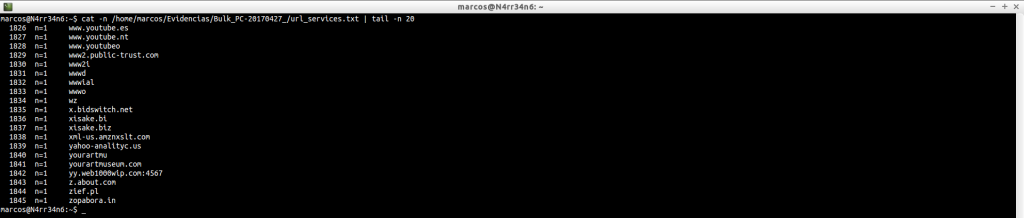
url_services.txt: Another file that gives us web addresses that have been found in the image file.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url_services.txt

We can get an idea of the information it contains.
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/url_services.txt | head -n 20
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/url_services.txt | tail -n 20
url.txt: File containing all the URLs found in the image file. Contains text in UTF-16 format. And it gives very useful information, to know what has been visited.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url.txt | head
cat /home/marcos/Evidencias/Bulk_PC-20170427_/url.txt | tail


Here we can use very interesting filters, in order firstly to make the information legible. This, for example, to look for websites, without being repeated the results.

Or this one, to look for web addresses that contain certain words.
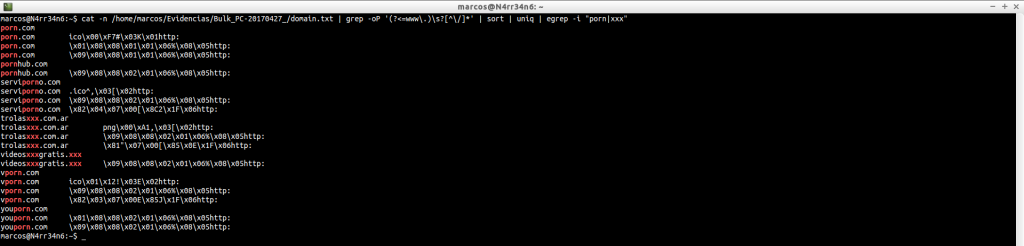
cat -n Evidencias/Bulk_PC-20170427_/url.txt | egrep -Eo «(http|https|www)://[a-zA-Z0-9./%&?=_-]*» | sort | uniq | egrep -i «xxx|porn|photo|video|jpg|jpeg» | head
cat -n Evidencias/Bulk_PC-20170427_/url.txt | egrep -Eo «(http|https|www)://[a-zA-Z0-9./%&?=_-]*» | sort | uniq | egrep -i «xxx|porn|photo|video|jpg|jpeg» | tail


Or we can simply tell him to show us the number of matches with those words.
![]()
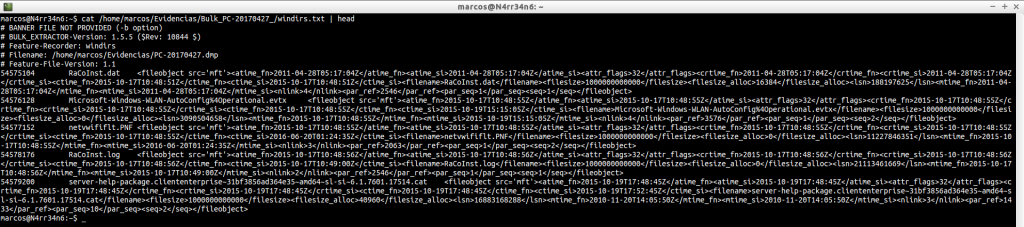
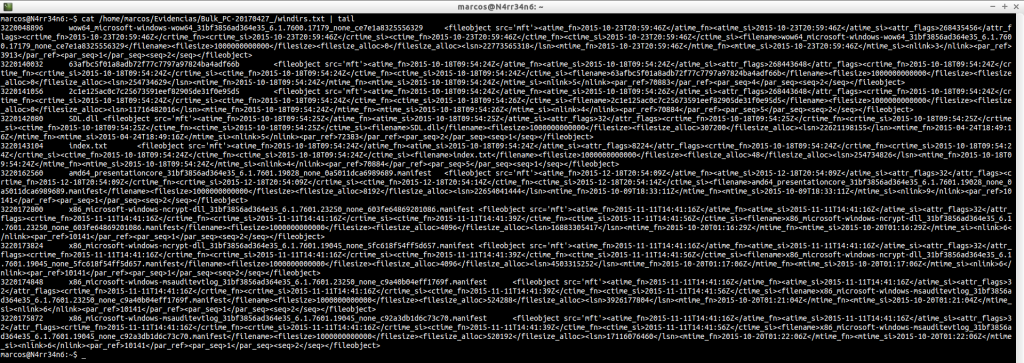
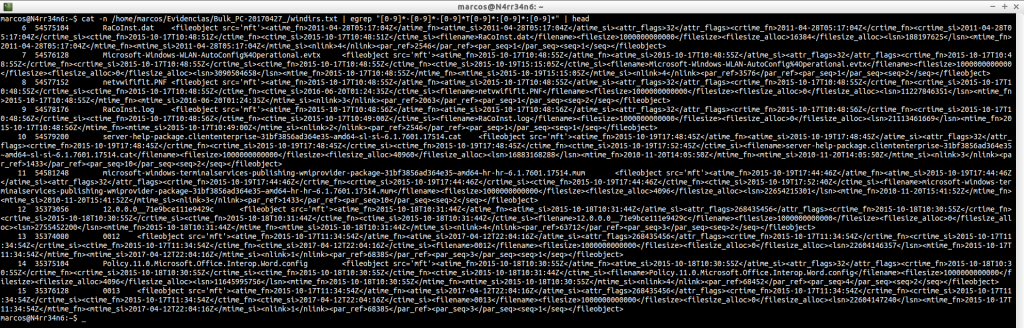
windirs.txt: It shows us the directory entries of Windows Systems. Its reading can become quite heavy.
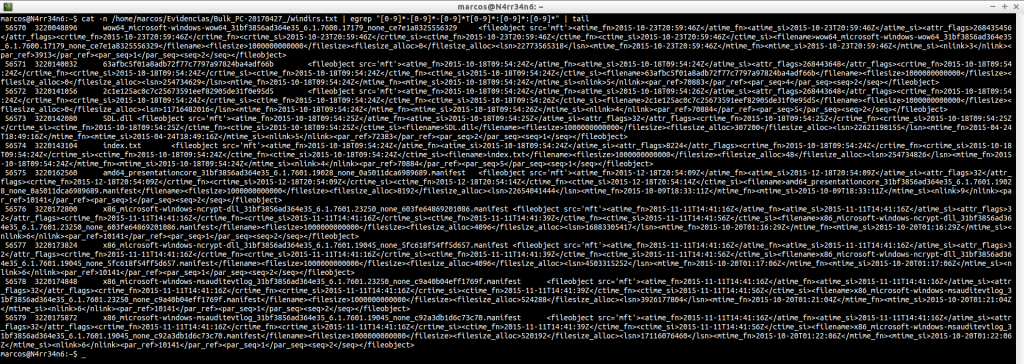
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/windirs.txt | head
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/windirs.txt | tail
But we could, for example, order them by establishing a chronological order
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/windirs.txt | egrep «[0-9]*-[0-9]*-[0-9]*T[0-9]*:[0-9]*:[0-9]*» | head
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/windirs.txt | egrep «[0-9]*-[0-9]*-[0-9]*T[0-9]*:[0-9]*:[0-9]*» | tail
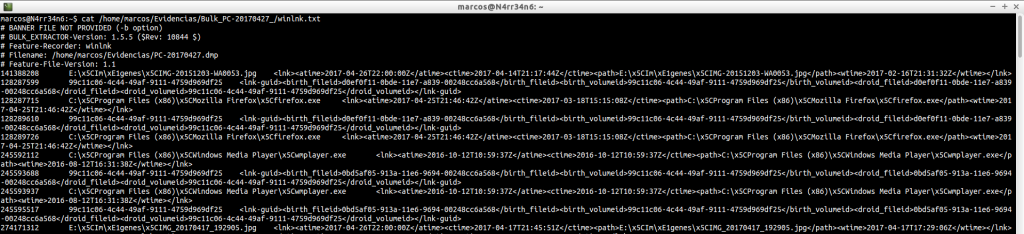
winlnk.txt: Find symbolic links, routes, in the image file. Very useful for searching file names, units, directories, …
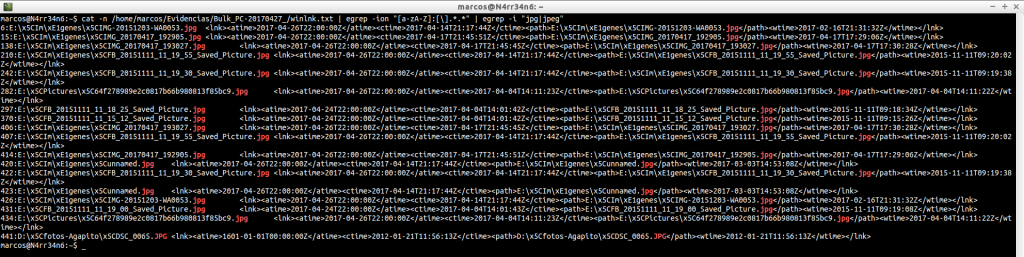
And we can refine the result, looking for matches with routes
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/winlnk.txt | egrep -ion «[a-zA-Z]:[\].*.*» | head
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/winlnk.txt | egrep -ion «[a-zA-Z]:[\].*.*» | tail


And we can still further filter the results, indicating, for example, that it shows us only one type of files.
winpe.txt: This file shows executables that are related to the Windows installation environment. It is usually examined when the case is related to some type of malware.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winpe.txt | head
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winpe.txt | tail

winprefetch.txt: Lists all system prefetch files, including deleted ones.
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winprefetch.txt

In this case, we can make filters by dates.
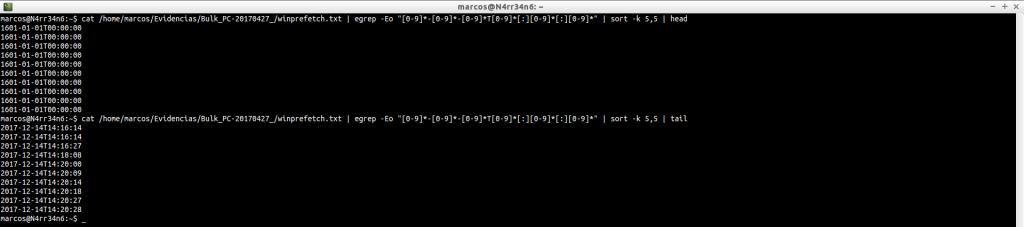
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winprefetch.txt | egrep -Eo «[0-9]*-[0-9]*-[0-9]*T[0-9]*[:][0-9]*[:][0-9]*» | sort -k 5,5 | head
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winprefetch.txt | egrep -Eo «[0-9]*-[0-9]*-[0-9]*T[0-9]*[:][0-9]*[:][0-9]*» | sort -k 5,5 | tail
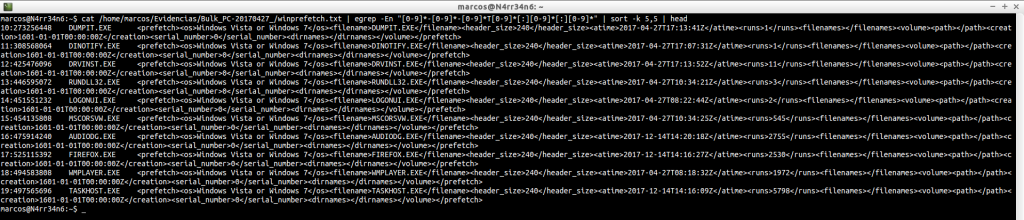
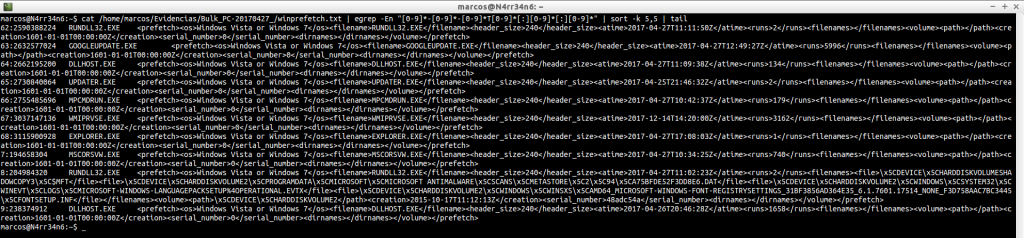
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winprefetch.txt | egrep -En «[0-9]*-[0-9]*-[0-9]*T[0-9]*[:][0-9]*[:][0-9]*» | sort -k 5,5 | head
cat /home/marcos/Evidencias/Bulk_PC-20170427_/winprefetch.txt | egrep -En «[0-9]*-[0-9]*-[0-9]*T[0-9]*[:][0-9]*[:][0-9]*» | sort -k 5,5 | tail
zip.txt: Scans and displays the contents of the ‘.zip’ files you have found.
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/zip.txt | head
cat -n /home/marcos/Evidencias/Bulk_PC-20170427_/zip.txt | tail

All this information is what has been obtained, or can be obtained, from, for example, a memory dump like the one we have seen. But, Can you analyze more files? As we mentioned at the beginning, (very above), yes. We can process, in the same way, a file ‘Pagefile.sys’, for example.
bulk_extractor -o /home/marcos/Evidencias/Pagefile_PC-20170427_/ /home/marcos/Evidencias/PC-20170427-Pagefile.sys


And we can see how much information can be obtained.

CONCLUSIONS
Bulk Extractor is a tool capable of extracting an enormous amount of information. In this case, where I intended to show you the ‘power’ of this software, I did not look for anything in particular. But since each case is a world, and there are no two similar analyzes, we have to be very clear in what we want to look for and we must worry about how to look for it, that’s what search patterns are for. It is of no use to have all this information if we are not able to process it, (as humans).
That is all, for now. See you at the next entry. This Minion, delivered and loyal to you, says goodbye… for now.
Marcos @_N4rr34n6_
Un comentario en «Who is Mr ‘X’? Let’s find out it with #BulkExtractor & #Egrep #Patterns – We are what we browser»
Thanks for sharing!
Los comentarios están cerrados.